
Định tính là gì? Ví dụ về nghiên cứu định tính và định lượng
Định tính là một trong những phương pháp nghiên cứu phổ biến nhất trong khoa học xã hội, marketing, tâm lý học và kinh tế học. Đây là cách tiếp cận giúp nhà nghiên cứu hiểu sâu sắc hơn về hành vi, cảm xúc, suy nghĩ và động cơ của con người – những yếu tố không thể đo lường được bằng con số.
1. Khái quát về định tính và định lượng
1.1. Định tính là gì?
Định tính (Qualitative Research) là phương pháp nghiên cứu tập trung vào việc thu thập và phân tích dữ liệu phi số học như văn bản, lời nói, hình ảnh, hoặc video. Mục tiêu của nghiên cứu định tính là hiểu sâu nguyên nhân, cách thức, và cảm xúc đằng sau hành vi của con người.
Khác với nghiên cứu định lượng – vốn tập trung vào đo lường và thống kê, nghiên cứu định tính quan tâm đến việc “tại sao” và “như thế nào” một hiện tượng xảy ra. Người nghiên cứu định tính thường đóng vai trò người quan sát hoặc người tham gia, khai thác cảm nhận thật của đối tượng thay vì chỉ thu thập số liệu.
1.2. Nghiên cứu định tính
Nghiên cứu định tính thường sử dụng các phương pháp như:
- Phỏng vấn sâu (In-depth Interview)
- Quan sát trực tiếp
- Thảo luận nhóm tập trung (Focus Group)
- Phân tích nội dung (Content Analysis)
Dữ liệu thu được trong nghiên cứu định tính mang tính “nội tại”, phản ánh trải nghiệm, suy nghĩ và cảm xúc của đối tượng nghiên cứu. Do đó, các dự án định tính thường có mẫu nhỏ, được chọn lọc kỹ càng thay vì chọn ngẫu nhiên.
Điểm mạnh của phương pháp định tính là khám phá sâu vấn đề, phát hiện quy luật hoặc khái niệm mới. Tuy nhiên, hạn chế chính là yếu tố chủ quan của người nghiên cứu trong quá trình phân tích và diễn giải dữ liệu.
1.3. Nghiên cứu định lượng là gì?
Nghiên cứu định lượng (Quantitative Research) là phương pháp thu thập và phân tích dữ liệu dưới dạng số học, thống kê. Mục tiêu là đo lường, kiểm định mối quan hệ giữa các biến, từ đó đưa ra kết luận có tính khái quát cho toàn bộ tổng thể.
Nghiên cứu định lượng thường dựa vào bảng hỏi, khảo sát trên quy mô lớn và sử dụng các công cụ phân tích dữ liệu như SPSS, Excel hoặc phần mềm thống kê chuyên dụng. Các bước cơ bản bao gồm:
- Xây dựng mô hình, giả thuyết
- Thiết kế bảng hỏi
- Thu thập và xử lý dữ liệu
- Phân tích thống kê, kiểm định mô hình
Mục tiêu của định lượng là lượng hóa dữ liệu để rút ra kết luận khách quan, chính xác và có thể tổng quát hóa.
2. So sánh dữ liệu định tính và định lượng
| Tiêu chí | Dữ liệu định tính | Dữ liệu định lượng |
|---|---|---|
| Mục đích nghiên cứu | Tìm hiểu sâu về hành vi, cảm xúc, động cơ – trả lời câu hỏi “Tại sao?” và “Như thế nào?” | Đo lường, kiểm định, mô hình hóa mối quan hệ – trả lời câu hỏi “Cái gì?”, “Bao nhiêu?”, “Ở đâu?”, “Khi nào?” |
| Phạm vi nghiên cứu | Nhỏ, tập trung vào chiều sâu, không đại diện cho toàn bộ tổng thể. | Rộng, đại diện cho tổng thể thông qua mẫu lớn và phương pháp thống kê. |
| Dạng dữ liệu | Văn bản, hình ảnh, ghi âm, video, quan sát – dữ liệu “phi số”. | Số liệu, tỷ lệ phần trăm, trung bình, phương sai – dữ liệu “số học”. |
| Phương pháp thu thập | Phỏng vấn sâu, thảo luận nhóm, quan sát. | Khảo sát bảng hỏi, đo lường, thống kê, mô phỏng. |
| Kết quả | Mô tả chi tiết, khám phá nguyên nhân, tạo nền tảng cho giả thuyết. | Kiểm định giả thuyết, cho ra kết quả định lượng cụ thể và khái quát hóa. |
3. Ví dụ về nghiên cứu định tính và định lượng

3.1. Ví dụ về nghiên cứu định lượng
Giả sử bạn muốn khảo sát mức độ hài lòng của khách hàng đối với hai mẫu xe ô tô của hãng A và hãng B. Bạn phát bảng câu hỏi cho 500 người, yêu cầu họ chấm điểm mức độ hài lòng từ 1 đến 5. Kết quả cho thấy 80% người tiêu dùng đánh giá cao mẫu mã của hãng A. Đây là ví dụ điển hình của nghiên cứu định lượng vì dữ liệu được biểu diễn bằng con số và phân tích thống kê.
3.2. Ví dụ về nghiên cứu định tính
Ngược lại, bạn muốn hiểu sâu hơn lý do vì sao khách hàng thích hoặc không thích mẫu xe của hãng A. Bạn tiến hành phỏng vấn sâu 10 người để họ chia sẻ về cảm nhận khi sử dụng xe: thiết kế, màu sắc, trải nghiệm lái, dịch vụ hậu mãi… Qua đó, bạn khám phá được các yếu tố cảm xúc và động cơ mua hàng – điều mà định lượng không thể hiện rõ. Đây chính là ví dụ của nghiên cứu định tính.
4. Kết luận
Định tính và định lượng là hai phương pháp nghiên cứu quan trọng, bổ trợ cho nhau trong quá trình phân tích dữ liệu và ra quyết định. Trong khi nghiên cứu định tính giúp hiểu sâu về cảm xúc và hành vi con người, thì nghiên cứu định lượng giúp kiểm chứng và khái quát hóa những phát hiện đó trên quy mô lớn hơn.
Hiểu rõ sự khác biệt và cách kết hợp hai phương pháp này sẽ giúp nhà nghiên cứu, doanh nghiệp hoặc marketer đưa ra quyết định chính xác, hiệu quả và toàn diện hơn.
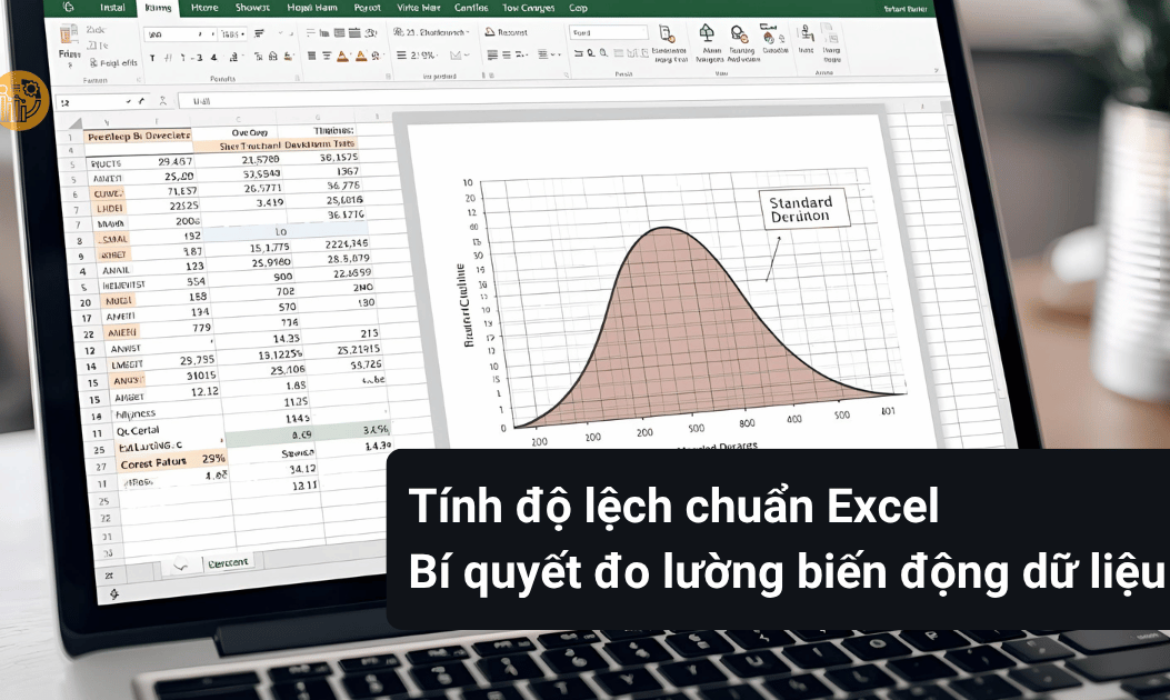
Tính độ lệch chuẩn Excel – Bí quyết đo lường biến động dữ liệu
Nắm vững cách tính độ lệch chuẩn là chìa khóa để phân tích dữ liệu hiệu quả, giúp bạn hiểu rõ hơn về sự phân tán và ổn định của các tập dữ liệu trong Excel.
Độ Lệch Chuẩn Là Gì?
Độ lệch chuẩn, hay còn gọi là standard deviation, là một chỉ số thống kê mô tả vô cùng quan trọng, đo lường mức độ phân tán của các điểm dữ liệu so với giá trị trung bình của tập dữ liệu đó. Hãy tưởng tượng bạn có một danh sách các điểm số của học sinh trong một lớp học. Nếu độ lệch chuẩn thấp, điều đó có nghĩa là hầu hết học sinh có điểm số gần với điểm trung bình của lớp, cho thấy sự đồng đều và ổn định trong thành tích. Ngược lại, nếu độ lệch chuẩn cao, đó là dấu hiệu cho thấy có sự chênh lệch lớn giữa các điểm số, có thể có những học sinh đạt điểm rất cao hoặc rất thấp so với mức trung bình. Việc hiểu rõ ý nghĩa này giúp chúng ta đưa ra những nhận định chính xác hơn về đặc điểm của tập dữ liệu, thay vì chỉ nhìn vào giá trị trung bình đơn thuần.
Trong thế giới kinh doanh và tài chính, độ lệch chuẩn đóng vai trò là thước đo rủi ro và sự biến động. Ví dụ, khi xem xét lợi nhuận của hai khoản đầu tư, nếu cả hai đều có cùng lợi nhuận trung bình, nhưng một khoản đầu tư có độ lệch chuẩn cao hơn, điều đó có nghĩa là khoản đầu tư đó có khả năng mang lại lợi nhuận biến động mạnh hơn, tiềm ẩn rủi ro cao hơn. Ngược lại, khoản đầu tư có độ lệch chuẩn thấp sẽ mang lại sự ổn định và có thể dự đoán được cao hơn. Do đó, việc tính độ lệch chuẩn không chỉ dừng lại ở việc thực hiện một phép tính toán học mà còn là một công cụ phân tích mạnh mẽ, giúp các nhà quản lý, nhà đầu tư đưa ra quyết định sáng suốt hơn dựa trên sự hiểu biết sâu sắc về tính không đồng nhất của dữ liệu.
Sự khác biệt giữa độ lệch chuẩn và phương sai cũng cần được làm rõ. Phương sai là giá trị trung bình của bình phương độ lệch so với trung bình, trong khi độ lệch chuẩn là căn bậc hai của phương sai. Việc lấy căn bậc hai giúp đưa đơn vị đo lường của độ lệch chuẩn trở về cùng đơn vị với dữ liệu gốc, làm cho nó dễ diễn giải hơn. Ví dụ, nếu bạn đang đo lường chiều cao bằng mét, phương sai sẽ có đơn vị là mét vuông, nhưng độ lệch chuẩn sẽ trở lại là mét, giúp việc so sánh và hiểu ý nghĩa trở nên trực quan hơn rất nhiều. Đây là lý do tại sao độ lệch chuẩn thường được ưa chuộng hơn trong các báo cáo và phân tích thực tế.
Công Thức Hàm STDEV
Khi nói đến việc tính độ lệch chuẩn trong Excel, hàm STDEV là công cụ đắc lực nhất. Công thức cơ bản của nó là: STDEV(number1, [number2], ...). Trong đó, number1 là đối số bắt buộc, đại diện cho giá trị đầu tiên trong tập dữ liệu bạn muốn phân tích. Các đối số tiếp theo, từ number2 trở đi, là tùy chọn và có thể lên đến 254 đối số khác, cho phép bạn bao gồm nhiều giá trị hoặc nhiều phạm vi dữ liệu khác nhau. Điều này mang lại sự linh hoạt cao cho người dùng, dù bạn có một danh sách các con số đơn lẻ hay nhiều nhóm dữ liệu cần phân tích đồng thời.
Một điểm mạnh của hàm STDEV là khả năng xử lý linh hoạt các loại đối số. Bạn không chỉ có thể nhập trực tiếp các con số, mà còn có thể thay thế chúng bằng một mảng dữ liệu (ví dụ: A1:A10) hoặc một tham chiếu tới một mảng. Quan trọng hơn, Excel rất thông minh trong việc bỏ qua các giá trị không phải số. Nếu trong phạm vi bạn chọn có các ô trống, giá trị logic (TRUE/FALSE), văn bản hoặc ký hiệu lỗi, chúng sẽ tự động bị loại trừ khỏi quá trình tính toán. Điều này giúp bạn tiết kiệm thời gian làm sạch dữ liệu và đảm bảo kết quả tính độ lệch chuẩn là chính xác dựa trên các giá trị số thực tế. Tuy nhiên, cần lưu ý rằng nếu bạn cố gắng chuyển đổi văn bản hoặc giá trị lỗi thành số mà không thành công, hàm sẽ trả về lỗi, do đó việc kiểm tra dữ liệu đầu vào là cần thiết.
Về mặt toán học, công thức độ lệch chuẩn mà Excel thực hiện ẩn sau hàm STDEV là việc tính căn bậc hai của phương sai mẫu. Cụ thể, nó tính trung bình của bình phương các độ lệch khỏi giá trị trung bình, sau đó lấy căn bậc hai. Công thức này dựa trên việc sử dụng n-1 ở mẫu số khi tính phương sai, đây là cách tính phương sai mẫu không chệch (unbiased sample variance), thường được sử dụng khi tập dữ liệu bạn có chỉ là một mẫu đại diện cho một tổng thể lớn hơn. Việc hiểu rõ nguyên tắc này giúp bạn tin tưởng hơn vào độ chính xác của kết quả mà Excel mang lại.
Cách Tính Độ Lệch Chuẩn Trong Excel

Để thực hiện cách tính độ lệch chuẩn trong Excel, quy trình vô cùng đơn giản và trực quan, ngay cả với người mới bắt đầu. Trước hết, bạn cần chuẩn bị dữ liệu của mình trong các ô tính. Giả sử bạn có một tập dữ liệu về doanh thu hàng năm của các khóa học như trong ví dụ đã cung cấp, với các năm 2020, 2021, 2022 nằm ở các cột C, D, E và tên khóa học ở cột B. Để tính độ lệch chuẩn cho khóa học “Tuyệt đỉnh Excel”, bạn sẽ chọn một ô trống (ví dụ: ô F2) nơi bạn muốn hiển thị kết quả. Sau đó, bạn chỉ cần nhập công thức =STDEV(C2:E2) vào ô đó và nhấn Enter. Excel sẽ tự động tính toán độ lệch chuẩn của các giá trị trong phạm vi từ C2 đến E2, đại diện cho doanh thu của khóa học này trong ba năm.
Sau khi đã tính được độ lệch chuẩn cho một khóa học, bạn có thể dễ dàng áp dụng cho các khóa học còn lại mà không cần nhập lại công thức. Bằng cách di chuyển con trỏ chuột đến góc dưới bên phải của ô chứa công thức (ô F2 trong ví dụ) cho đến khi nó biến thành một dấu cộng nhỏ màu đen, bạn có thể kéo ô đó xuống theo chiều dọc. Excel sẽ tự động điều chỉnh phạm vi dữ liệu cho từng hàng tương ứng, ví dụ, công thức ở ô F3 sẽ là =STDEV(C3:E3), tính độ lệch chuẩn cho khóa học tiếp theo. Phương pháp “kéo và sao chép” này không chỉ tiết kiệm thời gian mà còn giảm thiểu sai sót do nhập liệu thủ công, giúp bạn có được một bảng kết quả tính độ lệch chuẩn đầy đủ và chính xác cho toàn bộ tập dữ liệu.
Việc diễn giải kết quả ví dụ độ lệch chuẩn mà bạn nhận được cũng rất quan trọng. Như trong ví dụ, nếu khóa học “Tuyệt đỉnh Word” có độ lệch chuẩn thấp nhất, điều đó cho thấy doanh thu của khóa học này tương đối ổn định qua các năm, ít biến động. Ngược lại, khóa học “Tuyệt đỉnh Power Point” với độ lệch chuẩn cao nhất chỉ ra rằng doanh thu của nó biến động mạnh mẽ hơn, có thể có những năm tăng trưởng đột biến hoặc sụt giảm đáng kể. Đặc biệt, nếu xu hướng gần đây là giảm, như đã đề cập, điều này cần được chú ý hơn để có những chiến lược kinh doanh phù hợp. Việc so sánh các giá trị độ lệch chuẩn này giúp bạn đánh giá mức độ rủi ro, sự biến động và đưa ra các quyết định chiến lược dựa trên dữ liệu thực tế.
Phân Tích Sâu Hơn Với Excel SD Và Các Khái Niệm Thống Kê Liên Quan
Khi đã quen thuộc với việc tính độ lệch chuẩn bằng hàm STDEV, bạn có thể khám phá sâu hơn các khía cạnh khác của thống kê mô tả trong Excel. Một khái niệm liên quan mật thiết là phương sai. Mặc dù hàm STDEV đã tính toán nó ngầm định, bạn hoàn toàn có thể sử dụng hàm VAR.S (cho mẫu) hoặc VAR.P (cho tổng thể) để xem giá trị phương sai một cách độc lập. Hiểu mối quan hệ giữa phương sai và độ lệch chuẩn (độ lệch chuẩn là căn bậc hai của phương sai) sẽ củng cố kiến thức thống kê của bạn. Việc này hữu ích khi bạn cần phân tích chi tiết hơn về cách dữ liệu phân tán và hiểu rõ hơn về nguồn gốc của sự biến động.
Ngoài ra, Excel còn cung cấp các hàm khác hỗ trợ phân tích dữ liệu toàn diện hơn. Ví dụ, hàm AVERAGE giúp bạn tính giá trị trung bình, một thành phần cốt lõi trong việc tính toán độ lệch chuẩn. Hàm MEDIAN cho biết giá trị trung vị, hữu ích khi dữ liệu có thể bị ảnh hưởng bởi các giá trị ngoại lai. Hàm MODE.SNGL hoặc MODE.MULT giúp tìm ra các giá trị xuất hiện thường xuyên nhất trong tập dữ liệu. Khi kết hợp các hàm này với cách tính sd thông qua STDEV, bạn có thể xây dựng các báo cáo thống kê mô tả mạnh mẽ, cung cấp cái nhìn đa chiều về đặc điểm của dữ liệu, từ xu hướng trung tâm đến mức độ phân tán và sự tập trung của dữ liệu.
Việc nắm vững excel sd (standard deviation) và các hàm thống kê liên quan không chỉ giúp bạn thực hiện các phép tính mà còn trang bị cho bạn khả năng diễn giải kết quả một cách có ý nghĩa. Trong các ngữ cảnh thực tế, từ phân tích thị trường, đánh giá hiệu suất sản phẩm đến quản lý rủi ro tài chính, việc hiểu rõ mức độ biến động của dữ liệu là vô cùng quan trọng. Một độ lệch chuẩn cao có thể là dấu hiệu của cơ hội lớn nhưng cũng đi kèm với rủi ro cao, trong khi độ lệch chuẩn thấp thường ám chỉ sự ổn định và khả năng dự đoán tốt hơn. Do đó, việc sử dụng thành thạo các công cụ này trong Excel sẽ nâng cao đáng kể năng lực phân tích và ra quyết định của bạn. Việc hiểu rõ standard deviation formula giúp bạn tự tin hơn khi tiếp cận các bài toán thống kê phức tạp.
Kết Luận
Thông qua bài viết này, chúng ta đã khám phá chi tiết cách tính độ lệch chuẩn trong Excel bằng hàm STDEV, một công cụ mạnh mẽ giúp đo lường sự biến động của dữ liệu. Việc hiểu rõ ví dụ độ lệch chuẩn và cách áp dụng công thức độ lệch chuẩn không chỉ giúp bạn thực hiện các phép tính một cách nhanh chóng và chính xác mà còn nâng cao khả năng phân tích thống kê mô tả của mình. Sử dụng thành thạo excel sd và các hàm liên quan sẽ là lợi thế lớn trong công việc, giúp bạn đưa ra quyết định sáng suốt hơn dựa trên sự hiểu biết sâu sắc về dữ liệu.

PLS là gì? Giải mã sức mạnh dự đoán trong phân tích dữ liệu phức tạp
PLS là gì? Đây là câu hỏi mà nhiều nhà nghiên cứu và phân tích dữ liệu đặt ra khi tiếp cận với một phương pháp thống kê mạnh mẽ, đặc biệt hữu ích trong việc xử lý dữ liệu phức tạp và khám phá các mối quan hệ nhân quả. Bài viết này sẽ đi sâu vào bản chất của PLS-SEM, từ khái niệm cơ bản đến ứng dụng thực tế, giúp bạn hiểu rõ hơn về công cụ này và cách nó có thể giúp bạn giải quyết các vấn đề nghiên cứu của mình.
Thành phần của mô hình PLS-SEM
Mô hình PLS-SEM, hay Partial Least Squares Structural Equation Modeling, không chỉ là một công cụ thống kê, mà là một bức tranh toàn cảnh về mối quan hệ giữa các biến. Nó được chia thành hai phần chính, mỗi phần đóng một vai trò quan trọng trong việc giải mã câu chuyện mà dữ liệu đang kể.
Đầu tiên là mô hình đo lường (measurement model), nơi các biến quan sát (indicators) kết nối với các biến tiềm ẩn (latent variables). Có hai loại mô hình đo lường chính: phản xạ (reflective) và hình thành (formative). Trong mô hình phản xạ, các biến quan sát được xem là kết quả của biến tiềm ẩn. Ví dụ, sự hài lòng của khách hàng (biến tiềm ẩn) có thể được đo lường thông qua các biến quan sát như mức độ hài lòng với sản phẩm, dịch vụ, và sự sẵn lòng giới thiệu cho người khác. Ngược lại, trong mô hình hình thành, các biến quan sát đóng vai trò xây dựng nên biến tiềm ẩn. Ví dụ, chất lượng dịch vụ (biến tiềm ẩn) có thể được hình thành từ các biến quan sát như độ tin cậy, sự đáp ứng, và tính hữu hình. Việc lựa chọn đúng loại mô hình đo lường là rất quan trọng, vì nó ảnh hưởng trực tiếp đến cách chúng ta hiểu và diễn giải kết quả.
Thứ hai là mô hình cấu trúc (structural model), thể hiện mối quan hệ nhân quả giữa các biến tiềm ẩn. Mỗi đường dẫn (path) giữa hai biến tiềm ẩn đại diện cho một giả thuyết nghiên cứu. Hệ số của đường dẫn đó cho biết mức độ ảnh hưởng của biến này lên biến kia. Ví dụ, chúng ta có thể giả thuyết rằng nhận thức về giá trị (biến tiềm ẩn) có ảnh hưởng tích cực đến ý định mua hàng (biến tiềm ẩn). Mô hình cấu trúc cho phép chúng ta kiểm định các giả thuyết này và hiểu rõ hơn về cơ chế tác động giữa các biến. Việc kiểm định mô hình cấu trúc giúp đánh giá mức độ phù hợp của mô hình lý thuyết với dữ liệu thực tế.
Ưu điểm của PLS-SEM
PLS-SEM không phải ngẫu nhiên mà trở thành một công cụ được ưa chuộng trong nhiều lĩnh vực nghiên cứu. Nó sở hữu một loạt ưu điểm vượt trội, đặc biệt phù hợp với các nghiên cứu mang tính khám phá và ứng dụng thực tiễn.
Một trong những ưu điểm lớn nhất của PLS-SEM là khả năng làm việc hiệu quả với dữ liệu không tuân theo phân phối chuẩn. Trong khi các phương pháp SEM truyền thống như CB-SEM đòi hỏi dữ liệu phải tuân theo phân phối chuẩn, PLS-SEM lại linh hoạt hơn nhiều. Điều này có nghĩa là các nhà nghiên cứu có thể áp dụng PLS-SEM với dữ liệu thực nghiệm không chuẩn hóa mà vẫn đảm bảo độ tin cậy trong kết quả. Một ưu điểm nữa là PLS-SEM hoạt động tốt với kích thước mẫu nhỏ. Trong khi CB-SEM thường yêu cầu kích thước mẫu lớn (thường trên 200), PLS-SEM có thể hoạt động ổn định với cỡ mẫu từ 30–100 tuỳ vào độ phức tạp của mô hình. Đây là lợi thế quan trọng trong các nghiên cứu thực tế khi việc thu thập dữ liệu là một trở ngại.
Ngoài ra, PLS-SEM còn có khả năng xử lý mô hình phức tạp có nhiều biến tiềm ẩn và chỉ số quan sát. PLS-SEM còn cho phép mô hình hóa các mối quan hệ tuyến tính và phi tuyến, các mô hình bậc hai (second-order models), và thậm chí kết hợp với kỹ thuật phân cụm hoặc phân tích nhóm. Cuối cùng, PLS-SEM rất hiệu quả trong việc dự đoán hành vi. Mục tiêu chính của PLS-SEM là tối đa hóa phương sai giải thích của các biến phụ thuộc, do đó nó đặc biệt hữu ích trong các nghiên cứu tập trung vào dự đoán và giải thích.
Hạn chế của PLS-SEM
Tuy nhiên, cũng cần phải nhìn nhận một cách khách quan rằng PLS-SEM không phải là không có hạn chế. Việc hiểu rõ những hạn chế này sẽ giúp chúng ta sử dụng PLS-SEM một cách hiệu quả và tránh những sai lầm không đáng có.
Một trong những hạn chế lớn nhất của PLS-SEM là việc thiếu các chỉ số đánh giá độ phù hợp tổng thể của mô hình (global goodness-of-fit indices), như các chỉ số RMSEA hay CFI trong CB-SEM. Điều này khiến việc đánh giá mức độ phù hợp tổng thể của mô hình trong PLS-SEM khó khăn và đòi hỏi người dùng phải dựa vào nhiều chỉ số thành phần. Thứ hai, nếu nhà nghiên cứu không xác định rõ loại mô hình đo lường (phản xạ hay hình thành), việc ước lượng có thể bị sai lệch nghiêm trọng, dẫn đến kết luận sai lệch về mối quan hệ giữa các cấu trúc.
Ngoài ra, việc thiếu sự chuẩn hóa về báo cáo và diễn giải kết quả PLS-SEM cũng gây ra sự không nhất quán trong cộng đồng học thuật. PLS-SEM cũng có xu hướng tạo ra các mô hình có hệ số đường dẫn cao hơn mức thực tế nếu dữ liệu bị nhiễu hoặc thiếu điều kiện cần thiết, điều này có thể dẫn đến quá khớp (overfitting). Do đó, PLS-SEM nên được sử dụng với cẩn trọng, đặc biệt trong nghiên cứu xác nhận lý thuyết.
Ứng dụng của PLS-SEM

PLS-SEM không chỉ là một công cụ lý thuyết, mà còn là một phương pháp thực tiễn được ứng dụng rộng rãi trong nhiều lĩnh vực. Sự linh hoạt và khả năng xử lý dữ liệu phức tạp của nó đã khiến nó trở thành lựa chọn hàng đầu cho các nhà nghiên cứu và chuyên gia trong nhiều ngành khác nhau.
Trong lĩnh vực marketing, PLS-SEM là công cụ phổ biến để xây dựng và kiểm định mô hình hành vi người tiêu dùng, ví dụ như đánh giá ảnh hưởng của nhận thức thương hiệu, niềm tin và sự hài lòng lên ý định mua hàng. Nó cũng được sử dụng để nghiên cứu hiệu quả của các chiến dịch quảng cáo, đánh giá tác động của trải nghiệm khách hàng, và phân tích các yếu tố ảnh hưởng đến lòng trung thành của khách hàng. Trong lĩnh vực quản trị, PLS-SEM được sử dụng để nghiên cứu các yếu tố ảnh hưởng đến hiệu suất làm việc của nhân viên, đánh giá tác động của lãnh đạo, và phân tích các yếu tố ảnh hưởng đến sự thành công của dự án.
Ngoài ra, PLS-SEM còn được ứng dụng trong nhiều lĩnh vực khác như xã hội học, khoa học hành vi, công nghệ thông tin, và y tế. Ví dụ, trong lĩnh vực y tế, PLS-SEM có thể được sử dụng để nghiên cứu các yếu tố ảnh hưởng đến sức khỏe của bệnh nhân, đánh giá hiệu quả của các phương pháp điều trị, và phân tích các yếu tố ảnh hưởng đến sự tuân thủ điều trị của bệnh nhân.
Phần mềm hỗ trợ PLS-SEM
Để thực hiện phân tích PLS-SEM, chúng ta cần sử dụng các phần mềm chuyên dụng. Hiện nay, có nhiều phần mềm hỗ trợ PLS-SEM, mỗi phần mềm có những ưu điểm và nhược điểm riêng.
Một trong những phần mềm phổ biến nhất là SmartPLS. SmartPLS là một phần mềm thân thiện với người dùng, có giao diện trực quan và dễ sử dụng. Nó cung cấp đầy đủ các tính năng cần thiết để thực hiện phân tích PLS-SEM, bao gồm ước lượng mô hình, đánh giá mô hình đo lường, đánh giá mô hình cấu trúc, và tạo báo cáo kết quả. Một phần mềm khác cũng được sử dụng rộng rãi là ADANCO. ADANCO là một phần mềm mạnh mẽ, có khả năng xử lý các mô hình phức tạp và dữ liệu lớn. Nó cung cấp nhiều tính năng nâng cao, bao gồm phân tích đa nhóm, phân tích tiềm ẩn, và phân tích trung gian.
Ngoài ra, một số phần mềm thống kê khác như R và SPSS cũng có các gói lệnh hỗ trợ PLS-SEM. Tuy nhiên, việc sử dụng các phần mềm này đòi hỏi người dùng phải có kiến thức về lập trình và thống kê. Việc lựa chọn phần mềm phù hợp phụ thuộc vào nhu cầu và kinh nghiệm của người dùng. Nếu bạn là người mới bắt đầu, SmartPLS có thể là một lựa chọn tốt. Nếu bạn cần xử lý các mô hình phức tạp và dữ liệu lớn, ADANCO có thể phù hợp hơn.
So sánh PLS-SEM và CB-SEM

Khi nói đến mô hình hóa phương trình cấu trúc (SEM), hai phương pháp phổ biến nhất là PLS-SEM và CB-SEM (Covariance-Based SEM). Mặc dù cả hai đều được sử dụng để phân tích mối quan hệ giữa các biến, nhưng chúng có những khác biệt quan trọng về mục tiêu, phương pháp, và ứng dụng.
CB-SEM tập trung vào kiểm định sự phù hợp của mô hình lý thuyết với dữ liệu. Nó cố gắng tái tạo ma trận hiệp phương sai mẫu và đánh giá xem mô hình có phù hợp với dữ liệu hay không. Trong khi đó, PLS-SEM tập trung vào dự đoán và tối đa hóa phương sai giải thích của các biến phụ thuộc. Nó không cố gắng tái tạo ma trận hiệp phương sai mẫu, mà tập trung vào việc tìm ra các mối quan hệ mạnh nhất giữa các biến. CB-SEM đòi hỏi dữ liệu phải tuân theo phân phối chuẩn và có kích thước mẫu lớn (thường trên 200). PLS-SEM linh hoạt hơn và có thể được sử dụng với dữ liệu không chuẩn và kích thước mẫu nhỏ (từ 30-100).
CB-SEM cung cấp các chỉ số đánh giá độ phù hợp tổng thể của mô hình, như RMSEA và CFI. PLS-SEM không có các chỉ số này và việc đánh giá mô hình dựa trên nhiều chỉ số thành phần. CB-SEM thường được sử dụng trong nghiên cứu xác nhận lý thuyết, nơi các nhà nghiên cứu muốn kiểm tra xem một mô hình lý thuyết đã được thiết lập có phù hợp với dữ liệu hay không. PLS-SEM thường được sử dụng trong nghiên cứu khám phá, nơi các nhà nghiên cứu muốn tìm ra các mối quan hệ quan trọng giữa các biến và xây dựng lý thuyết mới.
Tiêu chí đánh giá mô hình PLS-SEM
Việc đánh giá mô hình PLS-SEM là một bước quan trọng để đảm bảo tính tin cậy và giá trị của kết quả nghiên cứu. Tuy nhiên, do PLS-SEM không có các chỉ số đánh giá độ phù hợp tổng thể của mô hình như CB-SEM, việc đánh giá mô hình PLS-SEM đòi hỏi sự cẩn trọng và sử dụng nhiều tiêu chí khác nhau.
Đầu tiên, chúng ta cần đánh giá mô hình đo lường. Đối với mô hình đo lường phản xạ, chúng ta cần đánh giá độ tin cậy (reliability) và tính hợp lệ (validity) của các biến quan sát. Độ tin cậy được đánh giá bằng hệ số Cronbach’s alpha và Composite Reliability (CR). Các giá trị này nên lớn hơn 0.7 để đảm bảo độ tin cậy của các biến quan sát. Tính hợp lệ được đánh giá bằng Average Variance Extracted (AVE). Giá trị AVE nên lớn hơn 0.5 để đảm bảo tính hợp lệ hội tụ (convergent validity) của các biến quan sát. Đối với mô hình đo lường hình thành, chúng ta cần đánh giá trọng số (weights) của các biến quan sát. Các trọng số này nên có ý nghĩa thống kê và có dấu phù hợp với lý thuyết.
Thứ hai, chúng ta cần đánh giá mô hình cấu trúc. Chúng ta cần đánh giá hệ số đường dẫn (path coefficients) giữa các biến tiềm ẩn. Các hệ số này nên có ý nghĩa thống kê và có dấu phù hợp với lý thuyết. Chúng ta cũng cần đánh giá hệ số R-squared (R²) của các biến phụ thuộc. Hệ số R² cho biết tỷ lệ phương sai của biến phụ thuộc được giải thích bởi các biến độc lập. Cuối cùng, chúng ta cần đánh giá kích thước hiệu ứng (effect size) của các mối quan hệ. Kích thước hiệu ứng cho biết mức độ ảnh hưởng của một biến lên biến khác.
Hướng dẫn thực hiện PLS-SEM
Thực hiện phân tích PLS-SEM đòi hỏi một quy trình có hệ thống và tuân thủ các bước cụ thể. Dưới đây là hướng dẫn chi tiết giúp bạn thực hiện phân tích PLS-SEM một cách hiệu quả.
Bước 1: Xác định mục tiêu nghiên cứu và xây dựng mô hình lý thuyết. Bước đầu tiên là xác định rõ mục tiêu nghiên cứu và xây dựng mô hình lý thuyết. Bạn cần xác định các biến tiềm ẩn và biến quan sát, mối quan hệ giữa chúng, và các giả thuyết nghiên cứu. Mô hình lý thuyết nên dựa trên các nghiên cứu trước đây và lý thuyết hiện có. Bước 2: Thu thập dữ liệu. Bước tiếp theo là thu thập dữ liệu. Bạn cần thu thập dữ liệu từ một mẫu đại diện cho quần thể nghiên cứu. Kích thước mẫu nên đủ lớn để đảm bảo độ tin cậy của kết quả. Bước 3: Chuẩn bị dữ liệu. Sau khi thu thập dữ liệu, bạn cần chuẩn bị dữ liệu cho phân tích. Bạn cần kiểm tra và làm sạch dữ liệu, xử lý các giá trị thiếu, và chuyển đổi dữ liệu nếu cần thiết.
Bước 4: Ước lượng mô hình. Bước tiếp theo là ước lượng mô hình PLS-SEM bằng phần mềm chuyên dụng như SmartPLS hoặc ADANCO. Bạn cần nhập dữ liệu vào phần mềm, chỉ định mô hình đo lường và mô hình cấu trúc, và chạy thuật toán PLS. Bước 5: Đánh giá mô hình. Sau khi ước lượng mô hình, bạn cần đánh giá mô hình. Bạn cần đánh giá mô hình đo lường và mô hình cấu trúc theo các tiêu chí đã nêu ở trên. Bước 6: Diễn giải kết quả. Cuối cùng, bạn cần diễn giải kết quả phân tích. Bạn cần trình bày các hệ số đường dẫn, hệ số R-squared, và các chỉ số khác. Bạn cần thảo luận về ý nghĩa của kết quả và so sánh chúng với các nghiên cứu trước đây.
Kết luận
PLS là gì? Đó là một công cụ mạnh mẽ để khám phá và dự đoán trong bối cảnh dữ liệu phức tạp. Từ việc xây dựng các mô hình đo lường và cấu trúc, đến việc đánh giá và diễn giải kết quả, PLS-SEM cung cấp một phương pháp toàn diện để hiểu rõ hơn về các mối quan hệ giữa các biến. Mặc dù có những hạn chế nhất định, nhưng với việc sử dụng cẩn trọng và hiểu biết sâu sắc, PLS-SEM có thể mang lại những đóng góp giá trị cho nghiên cứu và thực tiễn.

Standard Deviation Là Gì? Đo Lường Biến Động Dữ Liệu Hiệu Quả
Standard deviation là gì? Đây là một đại lượng thống kê quan trọng, dùng để đo lường mức độ phân tán hay sự biến thiên của một tập hợp dữ liệu so với giá trị trung bình của nó.
Standard Deviation Là Gì?
Độ lệch chuẩn (Standard Deviation), thường được viết tắt là SD, là một chỉ số thống kê phản ánh mức độ phân tán của các giá trị trong một tập dữ liệu so với giá trị trung bình của nó. Hiểu một cách đơn giản, nó cho chúng ta biết các điểm dữ liệu có xu hướng nằm gần hay xa giá trị trung bình. Khi standard deviation là gì có giá trị nhỏ, điều đó cho thấy các điểm dữ liệu tập trung gần giá trị trung bình, biểu thị sự ổn định và ít biến động. Ngược lại, một độ lệch chuẩn lớn chỉ ra rằng các điểm dữ liệu phân tán rộng rãi, xa rời giá trị trung bình, cho thấy sự biến động cao và tính không đồng nhất trong dữ liệu. Độ lệch chuẩn là căn bậc hai của phương sai (variance), một đại lượng khác cũng đo lường sự phân tán. Tuy nhiên, độ lệch chuẩn có ưu điểm là cùng đơn vị đo với dữ liệu gốc, giúp việc giải thích và so sánh trở nên trực quan và dễ hiểu hơn trong nhiều bối cảnh, từ tài chính, kiểm soát chất lượng đến nghiên cứu khoa học.
Khái Niệm Cơ Bản Về Độ Lệch Chuẩn
Standard deviation là gì khi xét về bản chất cốt lõi? Nó không chỉ là một con số khô khan mà là một lăng kính giúp chúng ta nhìn thấu sự biến động tiềm ẩn trong bất kỳ tập dữ liệu nào. Hãy tưởng tượng bạn có một nhóm học sinh với điểm số các bài kiểm tra khác nhau. Nếu điểm số của họ tập trung dày đặc quanh mức trung bình, độ lệch chuẩn sẽ thấp. Điều này cho thấy hầu hết học sinh có năng lực tương đương và không có sự chênh lệch quá lớn. Ngược lại, nếu điểm số trải dài từ rất thấp đến rất cao, độ lệch chuẩn sẽ cao, phản ánh sự khác biệt đáng kể về năng lực học tập giữa các em.
Trong thế giới tài chính, độ lệch chuẩn được ví như “sức khỏe” của một khoản đầu tư. Một cổ phiếu có độ lệch chuẩn cao có nghĩa là giá của nó biến động mạnh mẽ, mang lại cả cơ hội lợi nhuận cao lẫn rủi ro mất mát lớn. Ngược lại, một khoản đầu tư với độ lệch chuẩn thấp thường mang lại lợi nhuận ổn định hơn, ít biến động và do đó, rủi ro cũng thấp hơn. Việc hiểu rõ standard deviation là gì và cách nó hoạt động giúp các nhà đầu tư đưa ra quyết định sáng suốt, phù hợp với khẩu vị rủi ro của mình.
Vai Trò Của Độ Lệch Chuẩn Trong Phân Tích Dữ Liệu
Vai trò của độ lệch chuẩn trong phân tích dữ liệu là vô cùng quan trọng. Nó không chỉ cung cấp một con số định lượng về sự phân tán mà còn giúp chúng ta đánh giá độ tin cậy của các kết luận rút ra từ dữ liệu. Khi độ lệch chuẩn thấp, chúng ta có thể tự tin hơn rằng giá trị trung bình thực sự đại diện cho phần lớn dữ liệu. Ngược lại, độ lệch chuẩn cao có thể là dấu hiệu cảnh báo rằng giá trị trung bình có thể không phản ánh đầy đủ bức tranh tổng thể và cần xem xét kỹ lưỡng hơn các yếu tố khác.
Ví dụ, trong nghiên cứu y khoa, nếu một loại thuốc cho kết quả giảm huyết áp với độ lệch chuẩn thấp, điều này có nghĩa là thuốc có hiệu quả nhất quán trên đa số bệnh nhân. Tuy nhiên, nếu độ lệch chuẩn cao, nó có thể chỉ ra rằng thuốc có tác dụng mạnh ở một số người nhưng lại ít hiệu quả hoặc thậm chí gây tác dụng phụ ở những người khác. Do đó, độ lệch chuẩn giúp các nhà nghiên cứu đưa ra những đánh giá chính xác hơn về hiệu quả và tính an toàn của các phương pháp điều trị.
Minh Họa Trực Quan Về Sự Phân Tán Dữ Liệu
Để hình dung standard deviation là gì một cách trực quan, hãy thử tưởng tượng bạn đang ném bóng vào một mục tiêu. Nếu bạn ném rất chính xác, tất cả các quả bóng sẽ rơi gần tâm mục tiêu, tạo thành một cụm nhỏ. Điều này tương tự như một tập dữ liệu có độ lệch chuẩn thấp. Ngược lại, nếu cú ném của bạn không ổn định, các quả bóng sẽ rơi vãi khắp nơi, xa mục tiêu. Đây là hình ảnh của một tập dữ liệu có độ lệch chuẩn cao.
Sự khác biệt giữa độ lệch chuẩn thấp và cao có thể được biểu diễn bằng biểu đồ tần suất. Với độ lệch chuẩn thấp, đường cong biểu đồ sẽ cao và nhọn, tập trung xung quanh giá trị trung bình. Ngược lại, với độ lệch chuẩn cao, đường cong sẽ thấp và bè ra, cho thấy dữ liệu phân tán rộng hơn. Việc trực quan hóa này giúp bất kỳ ai, kể cả những người không chuyên về thống kê, cũng có thể nắm bắt được bản chất của sự biến động trong dữ liệu.
Tầm Quan Trọng Của Standard Deviation

Độ lệch chuẩn đóng vai trò như một “bộ lọc” thông tin, giúp chúng ta sàng lọc và hiểu rõ hơn về hành vi của dữ liệu. Trong một thế giới ngập tràn dữ liệu, khả năng đo lường và diễn giải sự biến động là vô cùng quý giá. Nó cho phép chúng ta đưa ra những quyết định dựa trên bằng chứng, đánh giá rủi ro một cách chính xác và tối ưu hóa hiệu quả trong nhiều lĩnh vực khác nhau. Từ việc dự đoán xu hướng thị trường đến đảm bảo chất lượng sản phẩm, độ lệch chuẩn luôn là một chỉ số không thể thiếu.
Đánh Giá Rủi Ro Và Độ Tin Cậy
Trong lĩnh vực tài chính, độ lệch chuẩn là thước đo phổ biến để đánh giá mức độ rủi ro của một khoản đầu tư. Độ lệch chuẩn càng cao thì mức độ biến động giá càng lớn, đồng nghĩa với rủi ro càng cao. Các nhà đầu tư sử dụng chỉ số này để so sánh các cơ hội đầu tư khác nhau và lựa chọn những khoản phù hợp với khả năng chấp nhận rủi ro của mình. Ví dụ, một quỹ đầu tư cổ phiếu tăng trưởng có thể có độ lệch chuẩn cao hơn so với một quỹ đầu tư trái phiếu chính phủ.
Không chỉ trong tài chính, độ lệch chuẩn còn giúp đánh giá độ tin cậy của các kết quả nghiên cứu. Trong khoa học, khi thử nghiệm một giả thuyết, độ lệch chuẩn cho biết mức độ biến thiên của các kết quả thu được. Nếu độ lệch chuẩn thấp, chúng ta có thể tin tưởng hơn rằng kết quả không phải là do ngẫu nhiên mà là phản ánh đúng bản chất của hiện tượng nghiên cứu. Ngược lại, độ lệch chuẩn cao có thể yêu cầu các nhà nghiên cứu thu thập thêm dữ liệu hoặc xem xét lại phương pháp thực nghiệm.
Kiểm Soát Chất Lượng Và Hiệu Suất
Trong sản xuất, độ lệch chuẩn là công cụ thiết yếu để kiểm soát chất lượng sản phẩm. Các nhà sản xuất thường đặt ra các tiêu chuẩn về kích thước, trọng lượng, hoặc các thông số kỹ thuật khác cho sản phẩm của mình. Độ lệch chuẩn giúp họ đo lường mức độ sai khác của các sản phẩm thực tế so với tiêu chuẩn. Nếu độ lệch chuẩn vượt quá ngưỡng cho phép, điều đó cho thấy có vấn đề trong quy trình sản xuất, cần phải điều chỉnh ngay lập tức để tránh sản xuất ra hàng loạt sản phẩm lỗi.
Tương tự, trong lĩnh vực dịch vụ, độ lệch chuẩn có thể được sử dụng để đánh giá hiệu suất và sự nhất quán của dịch vụ. Ví dụ, thời gian chờ đợi trung bình tại một nhà hàng có thể là một chỉ số quan trọng. Tuy nhiên, nếu thời gian chờ đợi có độ lệch chuẩn cao, điều đó có nghĩa là đôi khi khách hàng phải chờ rất lâu, trong khi đôi khi lại được phục vụ nhanh chóng. Sự biến động này có thể gây khó chịu cho khách hàng và ảnh hưởng đến uy tín của nhà hàng. Giữ cho độ lệch chuẩn thấp trong các quy trình dịch vụ là mục tiêu quan trọng để đảm bảo sự hài lòng của khách hàng.
Nền Tảng Cho Các Phân Tích Thống Kê Sâu Hơn
Standard deviation là gì khi đặt trong bức tranh lớn của thống kê? Nó là nền tảng cho nhiều kỹ thuật phân tích thống kê phức tạp hơn. Các khái niệm như khoảng tin cậy, kiểm định giả thuyết, phân tích hồi quy, và nhiều kỹ thuật khác đều dựa trên việc hiểu và sử dụng độ lệch chuẩn. Ví dụ, để xác định xem sự khác biệt giữa hai nhóm dữ liệu có ý nghĩa thống kê hay không, chúng ta thường so sánh độ lệch chuẩn của hai nhóm đó với sự khác biệt về giá trị trung bình.
Hơn nữa, độ lệch chuẩn giúp chúng ta hiểu được hình dạng của phân phối dữ liệu. Một phân phối chuẩn (normal distribution) có đặc điểm là đối xứng quanh giá trị trung bình, và độ lệch chuẩn xác định độ rộng của nó. Hiểu biết về hình dạng phân phối là rất quan trọng để lựa chọn các phương pháp phân tích phù hợp và diễn giải kết quả một cách chính xác. Do đó, nắm vững khái niệm độ lệch chuẩn là bước đầu tiên và quan trọng nhất để tiến sâu hơn vào thế giới của phân tích dữ liệu và thống kê.
Công Thức Tính Standard Deviation
Để thực sự làm chủ standard deviation là gì, việc hiểu rõ công thức tính toán là điều cần thiết. Công thức này không chỉ là một chuỗi ký hiệu toán học mà còn là một quy trình logic giúp chúng ta định lượng được sự phân tán của dữ liệu. Qua từng bước tính toán, chúng ta sẽ thấy rõ hơn cách mỗi điểm dữ liệu đóng góp vào bức tranh tổng thể về sự biến động.
Công Thức Tính Chi Tiết
Công thức tính độ lệch chuẩn cho tổng thể (population standard deviation, ký hiệu là $\sigma$) và cho mẫu (sample standard deviation, ký hiệu là $s$) có sự khác biệt nhỏ ở mẫu số.
Đối với tổng thể: $$ \sigma = \sqrt $$ Trong đó:
- $\sigma$: Độ lệch chuẩn của tổng thể.
- $x_i$: Giá trị thứ $i$ trong tập dữ liệu.
- $\mu$: Giá trị trung bình của tổng thể.
- $N$: Số lượng phần tử trong tổng thể.
- $\sum$: Ký hiệu tổng.
Đối với mẫu: $$ s = \sqrt $$ Trong đó:
- $s$: Độ lệch chuẩn của mẫu.
- $x_i$: Giá trị thứ $i$ trong tập dữ liệu mẫu.
- $\bar$) Cộng tất cả các giá trị lại và chia cho số lượng phần tử. $\bar = (5 + 8 + 12 + 15 + 20) / 5 = 60 / 5 = 12$.Bước 2: Tính độ lệch của từng giá trị so với giá trị trung bình Lấy từng giá trị trừ đi giá trị trung bình:
- $5 – 12 = -7$
- $8 – 12 = -4$
- $12 – 12 = 0$
- $15 – 12 = 3$
- $20 – 12 = 8$
Bước 3: Bình phương các độ lệch Bình phương mỗi kết quả từ Bước 2:
- $(-7)^2 = 49$
- $(-4)^2 = 16$
- $0^2 = 0$
- $3^2 = 9$
- $8^2 = 64$
Bước 4: Tính tổng các bình phương độ lệch Cộng tất cả các giá trị bình phương lại: $49 + 16 + 0 + 9 + 64 = 138$.
Bước 5: Tính phương sai mẫu ($s^2$) Chia tổng các bình phương độ lệch cho $(n-1)$, với $n=5$. $s^2 = 138 / (5-1) = 138 / 4 = 34.5$.
Bước 6: Tính độ lệch chuẩn mẫu ($s$) Lấy căn bậc hai của phương sai mẫu: $s = \sqrt$ cho mẫu và $\mu$ cho tổng thể.
- Phân phối chuẩn (Normal Distribution): Là một phân phối xác suất có hình dạng chuông đối xứng. Trong phân phối chuẩn, khoảng 68% dữ liệu nằm trong phạm vi một độ lệch chuẩn so với giá trị trung bình, khoảng 95% nằm trong hai độ lệch chuẩn, và khoảng 99.7% nằm trong ba độ lệch chuẩn.
- Sai số chuẩn (Standard Error – SE): Là độ lệch chuẩn của phân phối mẫu của một thống kê nào đó (ví dụ: độ lệch chuẩn của các giá trị trung bình mẫu). Nó đo lường mức độ chính xác của một ước lượng thống kê.
- Khoảng tin cậy (Confidence Interval): Là một phạm vi các giá trị có khả năng chứa tham số của tổng thể. Độ lệch chuẩn và sai số chuẩn là các yếu tố quan trọng trong việc tính toán khoảng tin cậy.
- Giá trị ngoại lai (Outlier): Là những điểm dữ liệu có giá trị khác biệt đáng kể so với phần còn lại của tập dữ liệu. Giá trị ngoại lai có thể ảnh hưởng lớn đến độ lệch chuẩn.
Câu hỏi thường gặp
Độ Lệch Chuẩn Cao Hay Thấp Thì Tốt Hơn?
Không có câu trả lời tuyệt đối cho câu hỏi này, vì “tốt hơn” phụ thuộc vào ngữ cảnh và mục tiêu phân tích.
- Độ lệch chuẩn thấp thường được xem là tốt trong các trường hợp đòi hỏi sự ổn định, nhất quán và khả năng dự đoán cao. Ví dụ:
- Trong sản xuất, độ lệch chuẩn thấp đảm bảo chất lượng sản phẩm đồng đều.
- Trong tài chính, độ lệch chuẩn thấp của một khoản đầu tư cho thấy rủi ro thấp hơn và lợi nhuận ổn định hơn.
- Trong y tế, độ lệch chuẩn thấp của kết quả điều trị cho thấy phương pháp đó có hiệu quả nhất quán trên nhiều bệnh nhân.
- Độ lệch chuẩn cao có thể là dấu hiệu của sự đa dạng, tiềm năng tăng trưởng lớn, hoặc sự khác biệt đáng kể. Ví dụ:
- Trong nghiên cứu khoa học, độ lệch chuẩn cao có thể chỉ ra sự khác biệt giữa các nhóm thử nghiệm, cần được điều tra sâu hơn.
- Trong các thị trường mới nổi, độ lệch chuẩn cao của giá cổ phiếu có thể phản ánh cơ hội đầu tư với tiềm năng lợi nhuận lớn, đi kèm với rủi ro cao.
- Trong giáo dục, độ lệch chuẩn cao trong điểm số có thể cho thấy sự đa dạng về năng lực của học sinh, đòi hỏi các phương pháp giảng dạy khác nhau cho từng nhóm.
Do đó, thay vì đánh giá cao hay thấp là tốt hơn, chúng ta cần hiểu độ lệch chuẩn phản ánh điều gì trong bối cảnh cụ thể để đưa ra đánh giá phù hợp.
Khi Nào Dùng Độ Lệch Chuẩn Của Tổng Thể Hoặc Của Mẫu?
Việc lựa chọn giữa độ lệch chuẩn của tổng thể ($\sigma$) và độ lệch chuẩn của mẫu ($s$) phụ thuộc vào bạn đang làm việc với toàn bộ dữ liệu hay chỉ một phần của nó.
- Sử dụng độ lệch chuẩn của tổng thể ($\sigma$): Khi bạn có dữ liệu của toàn bộ quần thể mà bạn quan tâm. Ví dụ, nếu bạn có điểm số của tất cả học sinh trong một lớp và muốn tính toán sự phân tán của điểm số đó, bạn sẽ sử dụng công thức cho tổng thể. Tuy nhiên, trường hợp này rất hiếm gặp trong thực tế vì việc thu thập toàn bộ dữ liệu của một tổng thể lớn thường tốn kém và khó khăn.
- Sử dụng độ lệch chuẩn của mẫu ($s$): Khi bạn chỉ có dữ liệu từ một mẫu được lấy ra từ một tổng thể lớn hơn, và bạn muốn sử dụng mẫu đó để ước lượng độ lệch chuẩn của tổng thể. Đây là trường hợp phổ biến nhất trong nghiên cứu và phân tích dữ liệu. Công thức tính độ lệch chuẩn của mẫu ($s$) sử dụng $(n-1)$ ở mẫu số để cung cấp một ước lượng không chệch (unbiased estimate) cho độ lệch chuẩn của tổng thể.
Hầu hết các phần mềm thống kê hiện đại sẽ tự động lựa chọn công thức phù hợp dựa trên cài đặt “tổng thể” hay “mẫu”, nhưng việc hiểu rõ nguyên tắc cơ bản này là rất quan trọng.
Có Công Cụ Nào Giúp Tính Toán Độ Lệch Chuẩn Nhanh Chóng Không?
Có, có rất nhiều công cụ giúp bạn tính toán độ lệch chuẩn một cách nhanh chóng và chính xác.
- Phần mềm bảng tính (Spreadsheet Software): Microsoft Excel, Google Sheets, và LibreOffice Calc đều có các hàm tích hợp sẵn để tính toán độ lệch chuẩn.
- Trong Excel/Google Sheets, bạn có thể sử dụng hàm
=STDEV.S(value1, [value2], ...)để tính độ lệch chuẩn của mẫu, hoặc=STDEV.P(value1, [value2], ...)để tính độ lệch chuẩn của tổng thể. - Bạn chỉ cần nhập hoặc chọn phạm vi dữ liệu của mình, và phần mềm sẽ trả về kết quả.
- Trong Excel/Google Sheets, bạn có thể sử dụng hàm
- Ngôn ngữ lập trình thống kê (Statistical Programming Languages):
- Python: Với các thư viện như NumPy và SciPy, việc tính toán độ lệch chuẩn trở nên rất đơn giản. Ví dụ,
numpy.std(data, ddof=1)sẽ tính độ lệch chuẩn của mẫu (ddof=1 là Delta Degrees of Freedom, tương đương chia cho n-1; mặc định là 0, chia cho n). - R: Ngôn ngữ R có sẵn hàm
sd(data)để tính độ lệch chuẩn của mẫu.
- Python: Với các thư viện như NumPy và SciPy, việc tính toán độ lệch chuẩn trở nên rất đơn giản. Ví dụ,
- Máy tính khoa học (Scientific Calculators): Nhiều máy tính khoa học hiện đại có chế độ thống kê, cho phép bạn nhập dữ liệu và trực tiếp tính toán các giá trị như trung bình, độ lệch chuẩn, và phương sai.
- Công cụ tính toán trực tuyến (Online Calculators): Có rất nhiều trang web cung cấp công cụ tính toán độ lệch chuẩn miễn phí. Bạn chỉ cần nhập dữ liệu của mình vào ô tương ứng và nhấn nút tính toán.
Các công cụ này giúp tiết kiệm thời gian và giảm thiểu sai sót so với việc tính toán thủ công, đặc biệt khi làm việc với các tập dữ liệu lớn.
Coefficient Of Variation Là Gì?
Coefficient of Variation (CV), hay Hệ số biến thiên, là một thước đo thống kê tương đối về sự phân tán của một tập dữ liệu. Nó được tính bằng cách chia độ lệch chuẩn cho giá trị trung bình, sau đó nhân với 100% để biểu thị dưới dạng phần trăm.
$$ CV = \left( \frac \right) \times 100\% $$ (Đối với mẫu)
Ý nghĩa của CV: CV cho phép so sánh mức độ biến động giữa các tập dữ liệu có thang đo hoặc giá trị trung bình khác nhau. Ví dụ, nếu bạn muốn so sánh sự biến động về giá cổ phiếu A (trung bình 100 USD, độ lệch chuẩn 20 USD) và giá cổ phiếu B (trung bình 10 USD, độ lệch chuẩn 5 USD):
- Cổ phiếu A: CV = (20 / 100) * 100% = 20%
- Cổ phiếu B: CV = (5 / 10) * 100% = 50%
Mặc dù độ lệch chuẩn của cổ phiếu A (20 USD) nhỏ hơn của cổ phiếu B (5 USD), nhưng CV của cổ phiếu A (20%) lại thấp hơn của cổ phiếu B (50%). Điều này cho thấy cổ phiếu B có mức độ biến động tương đối cao hơn so với giá trị trung bình của nó so với cổ phiếu A.
CV rất hữu ích khi so sánh sự biến động trong các lĩnh vực khác nhau, ví dụ như so sánh sự biến động về thu nhập giữa hai quốc gia có mức thu nhập trung bình khác nhau, hoặc so sánh sự biến động về chiều cao giữa hai loài động vật có kích thước trung bình khác nhau.
Kết luận
Standard deviation là gì đã được làm rõ thông qua định nghĩa, tầm quan trọng, công thức tính và các ứng dụng thực tế. Đây là một chỉ số thống kê thiết yếu, cung cấp cái nhìn sâu sắc về sự phân tán và biến động của dữ liệu. Hiểu và biết cách áp dụng độ lệch chuẩn không chỉ giúp chúng ta diễn giải thông tin một cách chính xác hơn mà còn hỗ trợ đưa ra các quyết định sáng suốt trong nhiều lĩnh vực của cuộc sống.

Reversed Question – Câu hỏi đảo ngược trong khảo sát và cách mã hóa trong SPSS
Trong quá trình thực hiện các nghiên cứu khảo sát, việc đảm bảo tính chính xác và độ tin cậy của dữ liệu luôn là ưu tiên hàng đầu. Trong đó, reversed question – hay còn gọi là câu hỏi đảo ngược – đóng vai trò quan trọng trong việc xác thực dữ liệu khảo sát, giúp phát hiện các phiếu khảo sát kém chất lượng, đồng thời kiểm tra tính nhất quán trong các câu trả lời của người tham gia. Hiểu rõ cách sử dụng câu hỏi đảo ngược trong bảng khảo sát và các mã hóa ngược SPSS phù hợp là bước then chốt để nâng cao độ tin cậy của thang đo khảo sát. Trong bài viết này, chúng ta sẽ cùng đi sâu vào các khái niệm, kỹ thuật và phương pháp cụ thể để tối ưu hóa quy trình kiểm tra độ tin cậy thang đo dựa trên reversed question.
1. Reversed Question là gì?
Reversed question là dạng câu hỏi được thiết kế theo chiều ngược lại với các câu hỏi thông thường trong bảng khảo sát. Nếu câu hỏi thuận chiều phản ánh ý kiến tích cực, thì câu hỏi đảo ngược phản ánh tiêu cực của cùng một thuộc tính. Mục tiêu là kiểm tra xem người trả lời có nhất quán hay không.
Ví dụ:
- Thuận chiều: “Tôi hài lòng với chất lượng sản phẩm.”
- Đảo ngược: “Sản phẩm khiến tôi thất vọng.”
Nếu người tham gia trả lời mâu thuẫn giữa hai câu hỏi này, có thể đó là dấu hiệu thiếu chú ý hoặc phản hồi không trung thực.
2. Vai trò của Reversed Question trong bảng khảo sát
Việc sử dụng câu hỏi đảo ngược mang lại nhiều lợi ích trong khảo sát:
- Kiểm tra tính nhất quán nội bộ của người trả lời.
- Giảm hiệu ứng xã hội (social desirability bias).
- Phát hiện và loại bỏ phản hồi không hợp lệ.
Các câu hỏi đảo ngược nên được xen kẽ hợp lý với các câu hỏi thuận chiều, tránh gây rối hoặc khiến người tham gia mệt mỏi.
3. Mã hóa ngược trong SPSS

Sau khi thu thập dữ liệu, cần mã hóa ngược (reverse coding) để các câu hỏi đảo ngược cùng chiều với thang đo chung. Dưới đây là cú pháp phổ biến trong SPSS:
COMPUTE Q1R = 6 - Q1.
EXECUTE.Hoặc sử dụng lệnh RECODE:
RECODE Q1 (1=5) (2=4) (4=2) (5=1).
EXECUTE.Với thang đo Likert 5 mức, mã hóa ngược đảm bảo giá trị 1 ↔ 5, 2 ↔ 4, và 3 giữ nguyên. Sau khi mã hóa, các biến đều phản ánh cùng chiều đo lường, giúp kiểm tra độ tin cậy dễ dàng hơn.
4. Reversed Question và kiểm tra độ tin cậy thang đo
Khi chạy Cronbach’s Alpha trong SPSS, việc mã hóa ngược đảm bảo:
- Hệ số Alpha phản ánh chính xác độ tin cậy.
- Các biến phản ánh cùng hướng đo lường.
- Dễ phát hiện biến hoặc phiếu khảo sát không nhất quán.
Nếu câu hỏi đảo ngược có hệ số tương quan thấp, cần xem xét loại bỏ để nâng cao độ tin cậy thang đo.
5. Reversed Question và câu hỏi kiểm tra sự chú ý
Reversed question còn được dùng như câu hỏi kiểm tra sự chú ý nhằm xác định người tham gia có thật sự đọc kỹ câu hỏi hay không.
Ví dụ: “Để đảm bảo bạn đang đọc kỹ, hãy chọn mức đồng ý thấp nhất cho câu hỏi này.”
Nhờ đó, nhà nghiên cứu dễ dàng loại bỏ các phản hồi ngẫu nhiên hoặc không hợp lệ.
6. Kết luận
Reversed question là công cụ hiệu quả giúp nâng cao độ tin cậy và tính chính xác của dữ liệu khảo sát. Khi được thiết kế và mã hóa đúng cách, reversed question hỗ trợ:
- Kiểm tra tính nhất quán trong phản hồi.
- Giảm sai lệch và phát hiện dữ liệu kém chất lượng.
- Tăng độ tin cậy của thang đo và giá trị khoa học của nghiên cứu.
Việc kết hợp reversed question và mã hóa ngược SPSS là bước không thể thiếu trong mọi nghiên cứu định lượng, giúp đảm bảo dữ liệu sạch, chính xác và đáng tin cậy.

Reverse là gì? Chấm điểm ngược Likert, SPSS & Alpha Cronbach
Trong các nghiên cứu khảo sát thuộc lĩnh vực xã hội học, tâm lý học hay kinh tế học, việc thiết kế câu hỏi sao cho phù hợp và đảm bảo tính chính xác của dữ liệu là điều vô cùng quan trọng. Một trong những kỹ thuật được sử dụng phổ biến để đảm bảo độ tin cậy và tính nhất quán trong phản hồi chính là reverse – hay còn gọi là đảo ngược. Vậy reverse là gì và nó có vai trò như thế nào trong quá trình phân tích dữ liệu?
Reverse là gì?
Reverse là gì trong ngữ cảnh nghiên cứu khảo sát chính là kỹ thuật đảo ngược các câu hỏi hoặc biến đo lường trong bảng hỏi nhằm tăng tính khách quan, hạn chế xu hướng trả lời theo mẫu hoặc theo cảm tính. Reverse giúp nhà nghiên cứu phát hiện các phản hồi không trung thực, kiểm tra tính nhất quán và loại bỏ các phiếu khảo sát kém chất lượng.
Về bản chất, reverse là quá trình đảo ngược hướng của câu hỏi trong thang đo – ví dụ, nếu một câu hỏi có nội dung tích cực, ta có thể thiết kế câu hỏi tương tự nhưng mang nội dung tiêu cực. Việc này như một “tấm gương phản chiếu” giúp kiểm tra xem người tham gia có đọc hiểu và trả lời nghiêm túc hay không.
Kỹ thuật reverse đặc biệt quan trọng trong các nghiên cứu sử dụng thang đo Likert. Nó giúp đảm bảo dữ liệu thu thập được phản ánh chính xác thái độ, niềm tin hoặc hành vi của người tham gia, đồng thời nâng cao độ tin cậy của mô hình đo lường.
Chấm điểm ngược thang Likert

Thang đo Likert thường được sử dụng để đo lường mức độ đồng ý hoặc không đồng ý với một phát biểu. Tuy nhiên, khi có các câu hỏi mang nội dung tiêu cực, ta cần thực hiện chấm điểm ngược (reverse scoring) để dữ liệu phản ánh chính xác hướng đo lường.
Chấm điểm ngược thang Likert là việc điều chỉnh lại điểm số sau khi thu thập dữ liệu. Ví dụ, với thang điểm từ 1 đến 5:
- Câu hỏi tích cực: điểm cao → thái độ tích cực.
- Câu hỏi tiêu cực: điểm cao → thái độ tiêu cực → cần đảo ngược (5 thành 1, 4 thành 2, v.v.).
Việc chấm điểm ngược giúp tất cả các câu hỏi cùng hướng về một ý nghĩa đo lường, tạo điều kiện thuận lợi cho việc tính toán các chỉ số như Cronbach’s Alpha hoặc EFA. Ngoài ra, nó còn giúp phát hiện các phản hồi mâu thuẫn, từ đó loại bỏ những phiếu khảo sát không trung thực.
Mã hóa lại biến trong SPSS
Sau khi thực hiện đảo câu hỏi, các nhà nghiên cứu cần tiến hành mã hóa lại biến trong SPSS để đảm bảo dữ liệu phân tích chính xác. Đây là bước chuẩn hóa giá trị của các biến sau khi chấm điểm ngược.
Trong SPSS, thao tác này được thực hiện bằng lệnh Recode. Ví dụ, nếu thang điểm ban đầu là từ 1 đến 5, sau khi đảo, ta mã hóa lại như sau: 1→5, 2→4, 3→3, 4→2, 5→1. Quá trình này đảm bảo các biến phản ánh đúng nội dung đo lường và tránh sai lệch trong quá trình tính toán.
Sau khi mã hóa, nên tiến hành kiểm tra lại độ tin cậy thang đo bằng Cronbach’s Alpha hoặc phân tích nhân tố khám phá (EFA) để đảm bảo các mục đo vẫn duy trì tính nhất quán.
Các mục có khóa âm
Các mục có khóa âm (negative keyed items) là những câu hỏi được thiết kế theo hướng tiêu cực nhằm kiểm tra tính nhất quán trong phản hồi. Ví dụ, thay vì hỏi “Tôi hài lòng với công việc của mình”, ta có thể hỏi “Tôi thường không cảm thấy hài lòng với công việc của mình”.
Việc sử dụng các mục có khóa âm giúp giảm thiểu sai lệch do người tham gia trả lời theo quán tính. Tuy nhiên, nếu không được xử lý đúng (đảo ngược và mã hóa lại), chúng có thể làm giảm độ tin cậy của thang đo.
Do đó, khi xử lý dữ liệu, các mục có khóa âm cần được chấm điểm ngược và mã hóa lại chính xác để phản ánh đúng hướng của khái niệm được đo lường.
Điều chỉnh Cronbach Alpha
Điều chỉnh Cronbach Alpha là bước cần thiết sau khi đã thực hiện đảo câu hỏi và mã hóa biến. Chỉ số này phản ánh độ tin cậy nội bộ của thang đo – nghĩa là các câu hỏi có cùng đo lường một khái niệm hay không.
Giá trị Cronbach’s Alpha thường được đánh giá như sau:
- Từ 0.6 trở lên: chấp nhận được.
- Từ 0.7 trở lên: đáng tin cậy.
- Từ 0.8 trở lên: rất tốt.
Nếu giá trị Alpha thấp, cần xem xét loại bỏ các mục làm giảm độ tin cậy, đặc biệt là các câu hỏi chưa được đảo ngược đúng cách hoặc không tương thích với nhóm đo lường.
Hiệu chỉnh sai lệch khảo sát
Trong nghiên cứu thực tế, sai lệch khảo sát là điều khó tránh khỏi – có thể do người trả lời không tập trung, hiểu sai câu hỏi, hoặc cố tình chọn ngẫu nhiên. Kỹ thuật reverse giúp phát hiện và hiệu chỉnh sai lệch khảo sát thông qua việc kiểm tra sự nhất quán giữa các câu hỏi cùng hướng.
Nhờ có reverse, nhà nghiên cứu có thể loại bỏ phiếu không hợp lệ, chuẩn hóa dữ liệu và đảm bảo các kết quả phân tích phản ánh trung thực hành vi, thái độ của đối tượng nghiên cứu.
Kết luận
Qua bài viết này, chúng ta đã hiểu rõ reverse là gì và tầm quan trọng của nó trong nghiên cứu khảo sát. Reverse không chỉ giúp phát hiện và hiệu chỉnh sai lệch khảo sát, mà còn hỗ trợ quá trình chấm điểm ngược thang Likert, mã hóa lại biến trong SPSS, xử lý các mục có khóa âm và điều chỉnh Cronbach Alpha để nâng cao độ tin cậy của thang đo.
Việc nắm vững và áp dụng đúng kỹ thuật reverse sẽ giúp các nhà nghiên cứu tạo ra bộ dữ liệu đáng tin cậy, phản ánh chính xác thái độ, hành vi và quan điểm của người tham gia – nền tảng quan trọng cho mọi quyết định khoa học và thực tiễn.

SPSS 20: Từ Cơ Bản Đến Nâng Cao (Kèm Ví Dụ)
Trong thời đại dữ liệu bùng nổ, việc chọn đúng công cụ phân tích thống kê là chìa khóa giúp các nhà nghiên cứu, doanh nghiệp và sinh viên chuyển đổi dữ liệu thành tri thức. Trong số hàng loạt phần mềm hiện nay, SPSS 20 nổi bật như phiên bản mạnh mẽ, ổn định và thân thiện nhất – đặc biệt phù hợp cho những ai muốn phân tích dữ liệu một cách nhanh, chính xác và chuyên nghiệp.
Vì sao nên chọn SPSS 20 thay vì các phiên bản khác?
SPSS 20 không chỉ là bản nâng cấp đơn thuần mà là bước nhảy vọt về hiệu năng và tính linh hoạt. Giao diện hiện đại, xử lý dữ liệu nhanh hơn và khả năng tương thích cao giúp người dùng làm chủ mọi phân tích – từ cơ bản đến nâng cao chỉ với vài thao tác chuột.
Phần mềm này được tối ưu hóa để chạy ổn định trên cả Windows, MacOS và Linux, đồng thời hỗ trợ xử lý dữ liệu lớn, cực kỳ hữu ích cho nghiên cứu khoa học, tài chính, giáo dục, marketing và y tế.
Những tính năng nổi bật của SPSS 20
- Thống kê mô tả: Tóm tắt nhanh các đặc trưng dữ liệu (trung bình, độ lệch chuẩn, phương sai…) chỉ trong vài giây.
- Phân tích ANOVA: So sánh sự khác biệt giữa các nhóm dữ liệu, giúp kiểm định giả thuyết chính xác.
- Hồi quy đa dạng: Hỗ trợ hồi quy tuyến tính, phi tuyến, logistic – từ mô hình đơn giản đến phức tạp.
- Xử lý dữ liệu thiếu: Cung cấp nhiều kỹ thuật thay thế linh hoạt (trung bình, hồi quy, multiple imputation…).
- Bảng tùy chỉnh thông minh: Thiết kế báo cáo trực quan, dễ đọc và xuất sang Excel, Word, PDF nhanh chóng.
Bảng so sánh SPSS 20 với các phần mềm phân tích dữ liệu khác
")
| Tiêu chí | SPSS 20 | Excel | R / Python | Stata / SAS |
|---|---|---|---|---|
| Độ thân thiện | ★★★★★ Giao diện trực quan, dễ học | ★★★ Dễ dùng nhưng hạn chế phân tích | ★★ Cần lập trình | ★★★ Phải hiểu cú pháp |
| Tốc độ xử lý dữ liệu lớn | ★★★★ | ★★ | ★★★★★ | ★★★★ |
| Khả năng thống kê nâng cao | ★★★★★ (ANOVA, hồi quy, EFA, CFA…) | ★★ | ★★★★★ | ★★★★★ |
| Khả năng trình bày & báo cáo | ★★★★★ | ★★★★ | ★★ | ★★★ |
| Độ ổn định, tương thích hệ điều hành | ★★★★★ | ★★★★★ | ★★★ | ★★★ |
| Đối tượng phù hợp | Sinh viên, nhà nghiên cứu, doanh nghiệp | Người mới học | Dữ liệu lớn, lập trình viên | Phân tích chuyên sâu |
Điểm khác biệt khiến SPSS 20 “đáng tiền”
- Không cần biết lập trình – mọi thao tác chỉ qua click chuột.
- Tích hợp sẵn hàng trăm phép phân tích – tiết kiệm thời gian.
- Báo cáo kết quả đẹp, tự động, chuẩn xuất bản.
- Tương thích cao – dùng được trên mọi hệ điều hành phổ biến.
- Tối ưu cho giáo dục & nghiên cứu khoa học, hỗ trợ xuất dữ liệu linh hoạt.
Download SPSS 20 Free 100%
Kết luận
Nếu bạn cần một phần mềm mạnh mẽ, dễ sử dụng và đáng tin cậy để xử lý, phân tích và trình bày dữ liệu, SPSS 20 chính là lựa chọn tối ưu. Đây là phiên bản kết hợp hoàn hảo giữa sức mạnh tính toán, giao diện thân thiện và khả năng mở rộng linh hoạt, phù hợp cho mọi cấp độ người dùng – từ sinh viên đến chuyên gia phân tích dữ liệu chuyên nghiệp.

SPSS Download and Install for Windows – Free 100%
Bạn đang tìm SPSS download miễn phí để phục vụ cho các mục đích phân tích dữ liệu trong học tập, nghiên cứu hay công việc? Bài viết này sẽ cung cấp cho bạn những thông tin cần thiết, hướng dẫn đầy đủ về cách tải, cài đặt và sử dụng phần mềm SPSS một cách dễ dàng và hiệu quả. Với khả năng giải quyết độ phức tạp của dữ liệu, dự báo chính xác và tối ưu hóa các chiến lược kinh doanh, IBM SPSS Statistics chính là công cụ không thể thiếu trong thời đại dữ liệu ngày nay.
Tính năng SPSS
SPSS không chỉ là phần mềm phân tích dữ liệu đơn thuần mà còn là nền tảng giúp người dùng chuyển đổi dữ liệu phức tạp thành thông tin giá trị, từ đó đưa ra các quyết định chính xác và chiến lược thông minh. Các tính năng của SPSS cung cấp khả năng tùy biến cao, giải quyết các bài toán từ đơn giản đến phức tạp, mang lại lợi ích vượt mong đợi cho người dùng.
Giải pháp toàn diện cho phân tích và dự báo
Một trong những điểm mạnh lớn nhất của SPSS là khả năng xử lý độ phức tạp của dữ liệu và dự báo không chắc chắn. Phần mềm này giúp người dùng có thể dự đoán các xu hướng tương lai, từ đó tối ưu hóa chiến lược kinh doanh hoặc các hoạt động nghiên cứu.
Ngoài ra, các nhà phân tích còn có thể tận dụng được khả năng lập trình cú pháp SPSS để tự động hóa các quy trình phân tích, từ đó tiết kiệm thời gian và tăng tính chính xác. Điểm đặc biệt nữa là việc nhập dữ liệu từ Excel sang SPSS cực kỳ dễ dàng, giúp những người mới tiếp cận không gặp nhiều bối rối khi chuyển đổi dữ liệu.
Bản quyền vĩnh viễn – đầu tư một lần, dùng mãi mãi
Với tùy chọn mua trọn gói vĩnh viễn từ 3.830 USD, người dùng sở hữu giấy phép bất cứ lúc nào họ muốn, không cần lo lắng về thuê bao hàng năm hoặc phí gia hạn. Đây là sự lựa chọn tối ưu cho những cá nhân hoặc tổ chức có ngân sách cố định và mong muốn sử dụng lâu dài mà không lo gián đoạn.
Đặc biệt, IBM còn cung cấp dùng thử miễn phí 14 ngày mà không yêu cầu cung cấp thẻ tín dụng. Người dùng có thể trải nghiệm đầy đủ các tính năng của SPSS, bao gồm các add-on có thể mua thêm, giúp đưa ra quyết định chính xác hơn về việc có nên đầu tư lâu dài hay không.
Tối ưu hóa ngân sách bằng chính sách dùng thử

Dùng thử miễn phí 14 ngày là cơ hội tuyệt vời để người dùng cảm nhận rõ ràng ích lợi của phần mềm này trước khi quyết định mua hoặc đăng ký thuê bao. Đây là chiến lược giúp IBM thu hút khách hàng mới, tạo điều kiện để họ khám phá các tính năng vượt trội như phân tích, lập kế hoạch, thu thập và báo cáo dữ liệu trong cùng một sản phẩm.
SPSS Download
Tổng kết
Như vậy, spss download không chỉ đơn thuần là một thao tác tải phần mềm, mà còn là bước mở ra cánh cửa đến thế giới phân tích dữ liệu đỉnh cao của IBM SPSS Statistics. Phần mềm này phù hợp với nhiều mục đích như tối đa hoá ROI marketing, dự báo doanh số, hỗ trợ y tế dựa trên bằng chứng, nghiên cứu thị trường hay hỗ trợ chính sách công.
Hãy bắt đầu Phiên bản dùng thử IBM SPSS ngay hôm nay, khám phá sức mạnh của phần mềm phân tích dữ liệu này để nâng cao năng lực và tạo ra những thành công vượt mong đợi. Đừng quên, việc nhập dữ liệu từ Excel sang SPSS hay lập trình cú pháp SPSS sẽ giúp bạn tối ưu hoá các quy trình, nâng cao hiệu suất công việc trong thời đại dữ liệu cạnh tranh này.

Biến Cố Độc Lập và Xác Suất SPSS: Hướng Dẫn Chi Tiết
Trong thống kê, biến cố độc lập đóng vai trò trung tâm trong việc phân tích dữ liệu và đưa ra các kết luận chính xác. Hiểu rõ về tính chất của biến cố này giúp nhà nghiên cứu phân tích mối quan hệ giữa các biến một cách rõ ràng hơn, đặc biệt khi làm việc với phần mềm SPSS. Qua bài viết này, chúng ta sẽ khám phá chi tiết về biến cố độc lập, cùng các phương pháp kiểm tra và áp dụng thực tế trong phân tích dữ liệu.
Biến cố độc lập là gì?
Biến cố độc lập là khái niệm cơ bản nhưng vô cùng quan trọng trong toán thống kê và xác suất. Đó là hai biến cố mà xảy ra hoặc không xảy ra theo cách độc lập lẫn nhau, nghĩa là kết quả của biến cố này không ảnh hưởng đến khả năng xảy ra của biến cố kia. Phân biệt rõ ràng giữa biến cố độc lập và liên quan giúp tránh những sai lầm trong phân tích dữ liệu, đặc biệt khi làm việc với những tập dữ liệu lớn hay trong các nghiên cứu khoa học.
Trong lý thuyết xác suất, hai biến cố A và B được gọi là biến cố độc lập khi việc xảy ra hay không xảy ra của biến cố này không ảnh hưởng đến xác suất xuất hiện của biến cố kia. Nói cách khác, dù biến cố A có xảy ra hay không, thì khả năng xảy ra của biến cố B vẫn giữ nguyên.
Định nghĩa: Hai biến cố A và B là độc lập khi và chỉ khi:
P(A ∩ B) = P(A) × P(B)
Công thức này còn được gọi là quy tắc nhân xác suất. Nếu có nhiều hơn hai biến cố (A₁, A₂, …, Aₖ) độc lập với nhau, thì:
P(A₁ ∩ A₂ ∩ … ∩ Aₖ) = P(A₁) × P(A₂) × … × P(Aₖ)
Hiểu rõ quy tắc này giúp bạn dễ dàng phân tích các hiện tượng ngẫu nhiên trong thực tế như kỹ thuật, tài chính, thống kê hoặc khoa học dữ liệu.
Ví dụ minh họa về biến cố độc lập
Ví dụ 1: Hệ thống hai động cơ máy bay
Xét một chiếc máy bay có hai động cơ (I và II), mỗi động cơ hoạt động hoàn toàn độc lập. Xác suất để động cơ I hoạt động tốt là 0,6 và động cơ II hoạt động tốt là 0,8. Hãy tính:
- a) Xác suất cả hai động cơ đều hoạt động tốt.
- b) Xác suất cả hai động cơ đều bị hỏng.
Lời giải:
a) Vì hai động cơ hoạt động độc lập nên:
P(A) = P(I chạy tốt) × P(II chạy tốt) = 0,6 × 0,8 = 0,48.
→ Xác suất cả hai động cơ hoạt động tốt là 48%.
b) Xác suất để động cơ I bị hỏng là: 1 – 0,6 = 0,4.
Xác suất để động cơ II bị hỏng là: 1 – 0,8 = 0,2.
Do hai động cơ hỏng độc lập nhau:
P(B) = 0,4 × 0,2 = 0,08.
→ Xác suất để cả hai động cơ đều hỏng là 8%.
Như vậy, khả năng để máy bay hoạt động ổn định cao hơn rất nhiều so với khả năng bị hỏng hoàn toàn. Đây là ví dụ điển hình về cách áp dụng quy tắc nhân xác suất trong biến cố độc lập.
Ví dụ 2: Gieo xúc xắc hai lần
Giả sử ta gieo một con xúc xắc cân đối hai lần liên tiếp. Gọi:
- A: “Lần gieo thứ nhất xuất hiện mặt có 4 chấm”.
- B: “Lần gieo thứ hai xuất hiện mặt có 4 chấm”.
Xác suất xuất hiện mặt 4 chấm trong mỗi lần gieo là 1/6. Vì hai lần gieo là độc lập, nên:
P(A ∩ B) = P(A) × P(B) = (1/6) × (1/6) = 1/36.
Điều này chứng tỏ A và B là biến cố độc lập vì xác suất đồng thời xảy ra bằng tích xác suất riêng lẻ của từng lần.
Một số bài tập tự luyện về biến cố độc lập

Dưới đây là một số bài tập để bạn thực hành nhận biết và tính toán xác suất của các biến cố độc lập.
Bài tập 1:
Một máy bay có hai động cơ A và B, mỗi động cơ hoạt động độc lập. Xác suất A hoạt động tốt là 0,5 và B hoạt động tốt là 0,9.
- a) Tính xác suất cả hai động cơ cùng hoạt động tốt.
- b) Tính xác suất cả hai động cơ cùng bị hỏng.
Bài tập 2:
Trong trò chơi may rủi, gieo một con xúc xắc hai lần. Xét hai biến cố:
- A: “Lần gieo đầu tiên ra mặt 6 chấm”.
- B: “Lần gieo thứ hai ra mặt 6 chấm”.
Hỏi hai biến cố A và B có độc lập không? Giải thích.
Bài tập 3:
Cho hai biến cố A và B là hai biến cố xung khắc (tức là không thể xảy ra đồng thời), với P(A) > 0 và P(B) > 0. Hãy chứng minh rằng A và B không thể là biến cố độc lập.
4. Ý nghĩa và ứng dụng của biến cố độc lập
Khái niệm biến cố độc lập không chỉ mang tính lý thuyết mà còn có giá trị thực tế trong nhiều lĩnh vực:
- Kỹ thuật: Dự đoán độ tin cậy của hệ thống có nhiều bộ phận hoạt động độc lập.
- Tài chính: Phân tích rủi ro giữa các khoản đầu tư không phụ thuộc nhau.
- Khoa học dữ liệu: Giả định độc lập giữa các biến giúp đơn giản hóa mô hình thống kê và machine learning.
- Giáo dục: Giúp học sinh, sinh viên hiểu rõ nền tảng xác suất và phân tích dữ liệu.
5. Kết luận
Qua các ví dụ và bài tập trên, ta thấy rằng việc nắm vững khái niệm biến cố độc lập giúp chúng ta hiểu sâu hơn về bản chất của các hiện tượng ngẫu nhiên. Việc áp dụng đúng quy tắc nhân xác suất không chỉ giúp giải toán nhanh chóng mà còn là công cụ quan trọng trong phân tích, dự báo và ra quyết định trong đời sống.

Phân Tích Dữ Liệu Định Tính: SPSS, NVivo, Mã Hóa Chủ Đề Hiệu Quả
Trong thế giới nghiên cứu, định tính là gì luôn là câu hỏi thu hút sự chú ý của các nhà khoa học, nhà phân tích. Nghiên cứu định tính là phương pháp tiếp cận toàn diện, khám phá sâu sắc về trải nghiệm, ý nghĩa, hành vi của con người trong môi trường tự nhiên, bằng cách sử dụng dữ liệu phi số như lời nói, hình ảnh, cử chỉ. Trong phạm vi này, việc hiểu rõ đặc điểm, phương pháp và quy trình để phân tích dữ liệu định tính trở thành yếu tố then chốt giúp các nhà nghiên cứu khai thác tối đa giá trị của dữ liệu, từ đó rút ra những kết luận chính xác và sâu sắc.
định tính là gì không chỉ đơn thuần là một phương pháp nghiên cứu, mà còn là một quá trình sáng tạo, đặt trọng tâm vào tính chủ quan, phản tư của nhà nghiên cứu, từ đó tạo ra những hiểu biết vô giá về các vấn đề phức tạp của xã hội. Hãy cùng khám phá chi tiết các khía cạnh của phương pháp nghiên cứu này qua từng phần nội dung dưới đây.
Nghiên cứu định tính là gì?
Nghiên cứu định tính là một phương pháp nghiên cứu tập trung vào việc khám phá, phân tích những hiện tượng mang tính sâu sắc, đa chiều và phức tạp của con người trong bối cảnh tự nhiên. Ưu điểm của phương pháp này nằm ở khả năng tiếp cận các dữ liệu phi số, như lời nói, hình ảnh và cử chỉ, giúp các nhà nghiên cứu hiểu rõ các ý nghĩa ẩn chứa đằng sau hành vi của đối tượng nghiên cứu.
Không giống như nghiên cứu định lượng, nghiên cứu định tính không cố gắng đo lường một cách chính xác hay khái quát hóa kết quả, mà tập trung vào việc diễn giải, phản ánh chiều sâu của trải nghiệm, dựa trên những gì thực tế và thân thuộc của người tham gia. Đặc điểm nổi bật của phương pháp này là linh hoạt trong thiết kế và sử dụng nhiều kỹ thuật khác nhau phù hợp với mục tiêu nghiên cứu, đặc biệt phù hợp để nghiên cứu trong các lĩnh vực như khoa học xã hội, giáo dục, nhân học, y tế cộng đồng.
Các đặc điểm nổi bật của nghiên cứu định tính
Ngoài việc khám phá về ý nghĩa và trải nghiệm, nghiên cứu định tính còn nhấn mạnh tính chủ quan trong quá trình phân tích dữ liệu. Điều này phản ánh rõ ràng trong phương pháp lấy phù hợp với tự nhiên, linh hoạt trong cách xác định câu hỏi và thiết kế nghiên cứu. Các nhà nghiên cứu có thể điều chỉnh hướng tiếp cận trong quá trình thực hiện, dựa trên dữ liệu thu thập được. Thậm chí, còn có thể khai thác các hướng tiếp cận như hiện tượng học, dân tộc học, tường thuật để khai thác tối đa chiều sâu của dữ liệu.
Nghiên cứu định tính còn là phương pháp đòi hỏi phản tư cao của nhà nghiên cứu, việc này giúp họ luôn giữ được tính khách quan trong quá trình diễn dịch dữ liệu. Hơn nữa, việc sử dụng dữ liệu phi số tạo điều kiện cho sự sáng tạo và phản biện sâu sắc, từ đó giúp phát hiện ra các mô hình, ý nghĩa chưa từng được nhận thức trước đây. Chính vì thế, phương pháp này còn được xem như một chốn đi sâu vào tâm hồn của các mối quan hệ, các sắc thái của cảm xúc trong đời sống hàng ngày.
Các phương pháp nghiên cứu định tính

Điểm mấu chốt của định tính là gì chính là khả năng áp dụng đa dạng các phương pháp tiếp cận và kỹ thuật thu thập dữ liệu để phù hợp với mục tiêu nghiên cứu. Thực tế, các phương pháp này phản ánh tính linh hoạt, sáng tạo và khả năng khai thác tối đa chiều sâu của dữ liệu phi số.
Trong thực tiễn, các phương pháp này mang nét đặc trưng riêng biệt, nhưng đều hướng đến mục tiêu hiểu biết sâu sắc các hiện tượng và hành vi con người trong khung cảnh tự nhiên. Việc lựa chọn phương pháp phù hợp đòi hỏi sự am hiểu rõ về đối tượng, câu hỏi nghiên cứu, cũng như khả năng phản biện của người thực hiện. Dưới đây là các hướng tiếp cận phổ biến và các phương pháp nghiên cứu định tính phổ biến nhất hiện nay.
Các phương pháp tiếp cận nghiên cứu định tính
Các phương pháp tiếp cận trong nghiên cứu định tính không chỉ đa dạng mà còn đan xen lẫn nhau, phù hợp cho từng mục tiêu và loại dữ liệu cần khai thác. Hiện tượng học, dân tộc học, tường thuật đều là các hướng tiếp cận nổi bật giúp khai thác các khía cạnh đặc thù của đời sống, hành vi, hay trải nghiệm của con người trong bối cảnh tự nhiên.
Trong đó, hiện tượng học chính là cách để các nhà nghiên cứu đi sâu vào trải nghiệm sống của cá nhân, nhằm tìm hiểu bản chất của trải nghiệm. Dân tộc học tập trung nghiên cứu đời sống văn hóa, tập quán của các cộng đồng, nhóm người, giúp nhận diện các đặc điểm xã hội đặc thù. Tường thuật khai thác các câu chuyện cá nhân, góp phần phát hiện ra các ý nghĩa mà đối tượng muốn chia sẻ qua các câu chuyện đời thường của mình.
Việc lựa chọn hướng tiếp cận phù hợp sẽ ảnh hưởng lớn đến kết quả nghiên cứu, yêu cầu người nghiên cứu cần có sự nhạy bén, phản biện để không bị lẫn lộn hoặc bỏ lỡ các chi tiết quan trọng. Một phương pháp không phù hợp sẽ dẫn đến dữ liệu thiếu khách quan hoặc thiếu chiều sâu, làm giảm giá trị của nghiên cứu.
Phương pháp nghiên cứu định tính phổ biến
Trong thực tế, để khai thác dữ liệu định tính hiệu quả, các nhà nghiên cứu thường sử dụng các phương pháp phổ biến như phỏng vấn trực tiếp, nghiên cứu quan sát, thảo luận nhóm tập trung, hoặc nghiên cứu điển hình. Mỗi phương pháp đều có ưu điểm riêng, phù hợp với các mục đích và đặc thù của từng nghiên cứu cụ thể.
Phỏng vấn trực tiếp giúp khai thác sâu quan điểm, kinh nghiệm cá nhân của người tham gia, đặc biệt hữu ích khi cần hiểu rõ các cảm xúc, suy nghĩ nội tâm. Nghiên cứu quan sát lại đóng vai trò nền tảng trong việc ghi nhận hành vi, tương tác trong bối cảnh thực tế, giúp phản ánh chân thực các sự kiện xảy ra. Trong khi đó, thảo luận nhóm tập trung cho phép khám phá các quan điểm đa chiều, từ đó làm rõ các mâu thuẫn, đa dạng trong ý kiến.
Nghiên cứu điển hình là cách tiến hành phân tích sâu một trường hợp hay hiện tượng cụ thể, giúp làm rõ các vấn đề phức tạp đang diễn ra. Các phương pháp này giúp các nhà nghiên cứu có thể xây dựng một bức tranh đầy đủ, đa chiều của hiện tượng, góp phần nâng cao tính thuyết phục của kết quả nghiên cứu.
Quy trình thực hiện nghiên cứu theo phương pháp định tính

Quy trình thực hiện nghiên cứu định tính tuy linh hoạt, nhưng phải tuân thủ theo một trình tự rõ ràng để đảm bảo tính hợp lý, khách quan, cũng như thuận tiện cho việc phân tích dữ liệu một cách bài bản. Mỗi bước trong quy trình đều mang ý nghĩa quan trọng, góp phần nâng cao chất lượng nghiên cứu.
Bước đầu tiên là xác định câu hỏi nghiên cứu, đây là nền móng để hướng dẫn toàn bộ quá trình, đòi hỏi nhà nghiên cứu xác định rõ mục tiêu, giới hạn và khung lý thuyết phù hợp. Tiếp theo, lựa chọn phương pháp phù hợp sẽ giúp tối đa hóa hiệu quả khai thác dữ liệu, đảm bảo tính phù hợp của kỹ thuật thu thập dữ liệu như phỏng vấn, quan sát hay tường thuật.
Việc xây dựng kế hoạch và chọn người tham gia là bước chuẩn bị kỹ lưỡng, đòi hỏi sự cẩn trọng trong lựa chọn mẫu, đảm bảo phản ánh đa dạng các góc nhìn. Thu thập dữ liệu là giai đoạn quan trọng, đòi hỏi sự linh hoạt, nhạy bén trong quá trình thực hiện. Phân tích dữ liệu sẽ dựa trên các kỹ thuật như mã hóa câu chuyện, phân loại chủ đề, hay xác định các mô hình hành vi, ý nghĩa. Cuối cùng, diễn giải, rút ra kết luận và truyền đạt kết quả sẽ giúp chuyển tải dữ liệu thành các bài học, kết luận có giá trị ứng dụng thực tiễn.
Các yếu tố cần chú ý trong quy trình
Trong toàn bộ quy trình, việc duy trì tính phản xạ, đạo đức, và độ tin cậy của dữ liệu là vô cùng quan trọng. Nhà nghiên cứu cần thường xuyên xem xét lại quá trình, cập nhật các khía cạnh chưa rõ ràng, và đảm bảo sự minh bạch trong phân tích. Các bước kiểm tra, lặp lại phân tích, cũng như lưu trữ tài liệu đầy đủ sẽ giúp tăng cường độ tin cậy của kết quả.
Không chỉ dừng lại ở việc thực hiện các bước, nhà nghiên cứu còn cần duy trì tính khách quan, tránh bị ảnh hưởng bởi các giả định chủ quan hay định kiến. Kết quả không chỉ dựa trên sự mô tả của người tham gia, mà còn cần dựa vào dữ liệu có tính khách quan, rõ ràng.
Ưu nhược điểm của nghiên cứu định tính
Trong bất kỳ phương pháp nghiên cứu nào, định tính là gì cũng đều có những ưu điểm và hạn chế riêng, điều này đòi hỏi nhà nghiên cứu phải cân nhắc kỹ lưỡng khi chọn lựa để áp dụng trong từng hoàn cảnh.
Ưu điểm
Nghiên cứu định tính nổi bật với khả năng khám phá chiều sâu của vấn đề, giúp các nhà phân tích đi sâu vào các khía cạnh phức tạp của hành vi, ý nghĩa, hoặc trải nghiệm. Nhờ đó, khả năng khai thác các dữ liệu phi số, như lời kể, hình ảnh hay cử chỉ, giúp hình thành các hiểu biết toàn diện hơn về đời sống, văn hóa hoặc các hiện tượng xã hội đa dạng.
Ngoài ra, phương pháp này còn giúp kích thích sự sáng tạo trong cách phân tích, thúc đẩy phản xạ tư duy của nhà nghiên cứu, qua đó nâng cao khả năng phát hiện các chiều sâu mới của vấn đề. Khả năng linh hoạt trong thiết kế và điều chỉnh quá trình nghiên cứu theo mức độ phù hợp của dữ liệu còn là điểm mạnh lớn của phương pháp này.
Nhược điểm
Mặt trái của định tính là gì chính là việc khó khách quan, thiếu tính thống nhất trong quá trình phân tích. Chúng ta dễ bị ảnh hưởng bởi quan điểm cá nhân của nhà nghiên cứu, khiến kết quả chưa rõ ràng hoặc chưa đủ đại diện cho tổng thể. Ngoài ra, việc phân tích dữ liệu định tính phức tạp, mất thời gian và công sức, đòi hỏi kỹ năng cao của nhà nghiên cứu.
Chất lượng dữ liệu phụ thuộc lớn vào trình độ, kĩ năng và đạo đức của người thực hiện, nên dễ dẫn đến sai lệch hoặc thiếu chính xác. Cuối cùng, việc khái quát hóa kết quả cũng gặp khó khăn do tính đặc thù trong từng trường hợp nghiên cứu, hạn chế khả năng ứng dụng rộng rãi của các kết quả này.
Một số lưu ý khi triển khai nghiên cứu định tính

Khi áp dụng định tính là gì vào thực tế, các nhà nghiên cứu cần lưu ý đến nhiều yếu tố nhằm đảm bảo kết quả có chất lượng và giá trị cao nhất. Một trong những yếu tố then chốt chính là rõ ràng trong xác định câu hỏi nghiên cứu, từ đó định hướng xuyên suốt quá trình thực nghiệm và phân tích.
Việc áp dụng khung lý thuyết phù hợp, thiết kế phù hợp, cũng như chọn mẫu người tham gia có tính khoa học là cơ sở để nâng cao tính khách quan và độ chính xác của dữ liệu. Bên cạnh đó, nhà nghiên cứu cần nâng cao độ tin cậy của dữ liệu bằng các kỹ thuật như mã hóa dữ liệu định tính, khai thác văn bản dữ liệu định tính một cách cẩn thận, hoặc dùng các phương pháp kết hợp như Phân tích nội dung SPSS và Mã hóa chủ đề tích hợp NVivo để tăng tính khách quan và phân tích sâu sắc.
Quan trọng nhất, duy trì tính phản xạ trong toàn bộ quá trình, tuân thủ đạo đức nghiên cứu và đảm bảo ghi chép lưu trữ dữ liệu đầy đủ, rõ ràng là những yếu tố đảm bảo cho sự thành công của dự án nghiên cứu. Phân tích lặp lại, kiểm tra chéo dữ liệu, sẽ giúp kiểm soát các sai lệch và nâng cao khả năng khái quát của kết quả nghiên cứu.
Kết luận
Định tính là gì thực sự là một phương pháp quan trọng, giúp các nhà nghiên cứu đi sâu vào các khía cạnh phức tạp của hành vi, ý nghĩa và trải nghiệm của con người trong các bối cảnh đa dạng. Phân tích dữ liệu định tính, kết hợp các công cụ như Phân tích nội dung SPSS, Mã hóa chủ đề tích hợp NVivo, hay Phân tích phương pháp hỗn hợp, đã giúp khai thác tối đa chiều sâu của dữ liệu phi số, từ đó tạo ra các hiểu biết mang tính hệ thống, có chiều sâu và có khả năng ứng dụng thực tiễn cao.
Sự linh hoạt, phản xạ và sáng tạo trong quy trình, cùng với ý thức đạo đức cao, sẽ giúp nâng cao chất lượng nghiên cứu định tính, từ đó đóng góp vào sự phát triển của các lĩnh vực nghiên cứu xã hội, nhân học, y tế cộng đồng và giáo dục.
Tổng kết lại, định tính là gì không chỉ là một phương pháp, mà còn là một triết lý nghiên cứu, nhằm khai thác tối đa ý nghĩa của từng cá nhân, từng câu chuyện, giúp chúng ta hiểu rõ hơn về thế giới phức tạp của con người và xã hội. Hãy luôn vận dụng sáng tạo, cẩn trọng và tôn trọng dữ liệu, để những nghiên cứu định tính trở thành những công cụ khảo sát chính xác, đáng tin cậy và mang lại hiệu quả thiết thực cao nhất.


