Hệ số xác định R² là gì? Ý nghĩa trong hồi quy
Trong phân tích thống kê và mô hình hóa dữ liệu, hệ số xác định là một trong những chỉ tiêu quan trọng nhất để đánh giá chất lượng của mô hình hồi quy tuyến tính. Rất nhiều người mới học thống kê thường đặt câu hỏi: Hệ số xác định là gì, R² nói lên điều gì và dùng thế nào cho đúng?
Bài viết này sẽ giúp bạn hiểu rõ bản chất của hệ số xác định, cách tính r bình phương (hay r squared), ý nghĩa của nó trong việc đánh giá độ phù hợp mô hình và khả năng giải thích biến thiên của biến phụ thuộc.
1. Hệ số xác định là gì?
Hệ số xác định (Coefficient of Determination), thường được ký hiệu là R², là một đại lượng thống kê dùng để đo lường mức độ mà mô hình hồi quy có thể giải thích biến thiên của biến phụ thuộc dựa trên các biến độc lập.
Nói một cách đơn giản, hệ số xác định cho biết:
“Bao nhiêu phần trăm sự biến động của Y được giải thích bởi mô hình?”
Trong hồi quy tuyến tính, R² là chỉ số được sử dụng phổ biến nhất để đánh giá độ phù hợp mô hình.
2. Giá trị và phạm vi của hệ số xác định
Giá trị của hệ số xác định luôn nằm trong khoảng từ 0 đến 1:
- R² = 0: mô hình không giải thích được biến thiên của biến phụ thuộc
- R² = 1: mô hình giải thích hoàn toàn biến thiên của biến phụ thuộc
- 0 < R² < 1: mô hình giải thích được một phần biến thiên
Ví dụ: nếu hệ số xác định R² = 0.65, có thể hiểu rằng khoảng 65% sự biến động của biến phụ thuộc được giải thích bởi các biến độc lập trong mô hình.
3. Mối quan hệ giữa hệ số xác định và r bình phương
Trong hồi quy tuyến tính đơn, hệ số xác định chính là r bình phương (bình phương hệ số tương quan Pearson).
Công thức:
R² = r²
Trong đó:
- r là hệ số tương quan tuyến tính giữa X và Y
- r squared (r²) thể hiện mức độ liên hệ tuyến tính
Trong hồi quy đa biến, hệ số xác định không còn đơn thuần là bình phương của một hệ số tương quan, mà phản ánh tổng thể mức độ giải thích của toàn bộ mô hình.
4. Cách tính hệ số xác định
Để tính hệ số xác định, ta dựa trên các đại lượng sau:
- SSE – Tổng bình phương sai số
- SST – Tổng bình phương tổng
4.1. Tổng bình phương sai số (SSE)
SSE đo lường mức độ sai lệch giữa giá trị thực tế và giá trị dự đoán của mô hình:
SSE = Σ (y − ŷ)²
4.2. Tổng bình phương tổng (SST)
SST đo lường tổng mức độ biến thiên của biến phụ thuộc so với giá trị trung bình:
SST = Σ (y − ȳ)²
4.3. Công thức hệ số xác định
Từ đó, hệ số xác định được tính như sau:
R² = 1 − (SSE / SST)
Công thức này thể hiện rõ bản chất của R²: tỷ lệ phần biến thiên được mô hình giải thích.
5. Ý nghĩa của hệ số xác định trong hồi quy tuyến tính

Trong hồi quy tuyến tính, hệ số xác định có nhiều ý nghĩa quan trọng:
- Đánh giá độ phù hợp mô hình
- So sánh các mô hình hồi quy trên cùng một tập dữ liệu
- Đánh giá khả năng giải thích biến thiên của biến phụ thuộc
Tuy nhiên, cần lưu ý rằng hệ số xác định cao không đồng nghĩa với mô hình luôn đúng về mặt nhân quả.
6. Ứng dụng của hệ số xác định
Hệ số xác định được sử dụng rộng rãi trong nhiều lĩnh vực:
6.1. Đánh giá mô hình dự báo
Trong các bài toán dự báo, R² cho biết mô hình có đáng tin cậy hay không khi sử dụng để dự đoán giá trị tương lai.
6.2. So sánh mô hình
Khi xây dựng nhiều mô hình hồi quy khác nhau, hệ số xác định giúp lựa chọn mô hình có khả năng giải thích tốt hơn.
6.3. Phân tích dữ liệu kinh doanh
Trong kinh doanh, R² thường được dùng để đánh giá mức độ ảnh hưởng của các yếu tố như giá, quảng cáo, chất lượng dịch vụ đến doanh thu.
6.4. Nghiên cứu khoa học
Trong nghiên cứu học thuật, hệ số xác định giúp đánh giá mức độ thuyết phục của mô hình lý thuyết.
7. Những hiểu lầm thường gặp về hệ số xác định
- R² cao không có nghĩa là mô hình đúng về mặt nhân quả
- R² thấp không đồng nghĩa mô hình vô dụng
- Thêm nhiều biến độc lập luôn làm R² tăng
Vì vậy, khi đánh giá mô hình, không nên chỉ nhìn vào hệ số xác định mà cần kết hợp với các kiểm định khác.
8. Hệ số xác định và độ phù hợp mô hình
Độ phù hợp mô hình không chỉ phụ thuộc vào R² mà còn liên quan đến:
- Kiểm định F
- Ý nghĩa thống kê của các hệ số
- Kiểm tra giả định hồi quy
Hệ số xác định nên được xem là một chỉ báo tổng quát, không phải tiêu chí duy nhất.
9. Kết luận
Hệ số xác định (R²) là thước đo quan trọng giúp đánh giá khả năng giải thích biến thiên của mô hình hồi quy tuyến tính. Việc hiểu đúng bản chất của r bình phương và r squared giúp bạn đọc kết quả phân tích một cách chính xác và khoa học hơn.
Nếu bạn đang học thống kê, phân tích dữ liệu hoặc làm luận văn, hãy sử dụng hệ số xác định một cách cẩn trọng, kết hợp cùng các chỉ tiêu khác để đánh giá toàn diện mô hình.
Bạn có thể tham khảo thêm các bài hướng dẫn chuyên sâu tại xulysolieu.info – Xử lý số liệu hoặc liên hệ 0878968468 để được hỗ trợ chi tiết trong phân tích hồi quy và SPSS.
Kiểm định phương sai ANOVA trong SPSS
Kiểm định phương sai ANOVA là một kỹ thuật thống kê quan trọng, được sử dụng phổ biến trong phân tích dữ liệu nhằm so sánh giá trị trung bình của nhiều nhóm đối tượng khác nhau. Trong các nghiên cứu kinh tế – xã hội, marketing, quản trị hay giáo dục, kiểm định phương sai ANOVA gần như là công cụ bắt buộc khi biến phân loại có từ hai nhóm trở lên.
Bài viết này trình bày một cách hệ thống về kiểm định phương sai ANOVA, cách đọc kết quả trong SPSS và cách áp dụng trong nghiên cứu thực tế, theo hướng dễ hiểu và thực hành được ngay.
1. Kiểm định phương sai ANOVA là gì?
Kiểm định phương sai ANOVA (Analysis of Variance) là phương pháp thống kê dùng để so sánh giá trị trung bình của từ hai nhóm trở lên dựa trên sự biến thiên của dữ liệu. Thay vì so sánh từng cặp như kiểm định t-test, kiểm định phương sai ANOVA cho phép đánh giá đồng thời nhiều nhóm trong một phép kiểm định duy nhất.
Trong bối cảnh one way ANOVA, ta có:
- Một biến định lượng (biến phụ thuộc)
- Một biến định tính (biến độc lập) có từ hai nhóm trở lên
Mục tiêu của kiểm định phương sai ANOVA là xác định liệu trung bình của các nhóm có khác biệt một cách có ý nghĩa thống kê hay không.
2. Khi nào sử dụng kiểm định phương sai ANOVA?
Kiểm định phương sai ANOVA được sử dụng trong các trường hợp:
- So sánh sự hài lòng của khách hàng theo nhiều nhóm độ tuổi
- So sánh động lực làm việc giữa các trình độ học vấn khác nhau
- So sánh hành vi mua hàng giữa nhiều nhóm thu nhập
Khi biến định tính chỉ có 2 nhóm, kết quả kiểm định phương sai ANOVA cho ra hoàn toàn tương đương với Independent Sample T-Test. Do đó, nhiều nhà nghiên cứu ưu tiên dùng ANOVA cho mọi trường hợp so sánh nhiều nhóm để đảm bảo tính nhất quán phương pháp.
3. Giả thuyết trong kiểm định phương sai ANOVA
Trong giả thuyết ANOVA, ta luôn đặt hai giả thuyết cơ bản:
- H0: Không có sự khác biệt trung bình giữa các nhóm
- H1: Có ít nhất một cặp nhóm có trung bình khác nhau
Kiểm định phương sai ANOVA không chỉ ra nhóm nào khác nhóm nào, mà chỉ cho biết có hay không sự khác biệt tổng thể giữa các nhóm.
4. Quy trình kiểm định phương sai ANOVA trong SPSS

Quy trình thực hiện kiểm định phương sai ANOVA trong SPSS gồm hai bước chính.
Bước 1: Kiểm định sự đồng nhất phương sai
Trước khi so sánh trung bình, kiểm định phương sai ANOVA yêu cầu kiểm tra sự đồng nhất phương sai giữa các nhóm bằng kiểm định Levene.
Giả thuyết:
- HL0: Phương sai giữa các nhóm là bằng nhau
Kết quả kiểm định Levene:
- Sig > 0.05: phương sai không khác biệt → dùng f-test trong bảng ANOVA
- Sig < 0.05: phương sai khác biệt → dùng kiểm định Welch
Bước 2: Kiểm định sự khác biệt trung bình
Sau khi xác định phương sai, kiểm định phương sai ANOVA tiến hành kiểm tra sự khác biệt trung bình:
- Dùng f-test nếu phương sai đồng nhất
- Dùng Welch nếu phương sai không đồng nhất
Kết quả:
- Sig < 0.05: Bác bỏ H0 → Có sự khác biệt trung bình
- Sig > 0.05: Chấp nhận H0 → Không có sự khác biệt trung bình
5. Thực hành kiểm định phương sai ANOVA trong SPSS
Để thực hiện kiểm định phương sai ANOVA trong SPSS:
- Vào Analyze → Compare Means → One-Way ANOVA
- Đưa biến định lượng vào Dependent List
- Đưa biến định tính vào Factor
- Chọn Options và tích các mục Descriptive, Homogeneity of variance test, Welch
SPSS sẽ xuất ra các bảng: Descriptives, Test of Homogeneity of Variances, ANOVA và Robust Tests of Equality of Means.
6. Diễn giải kết quả kiểm định phương sai ANOVA
Khi đọc kết quả kiểm định phương sai ANOVA, cần lưu ý:
- Kết luận dựa trên giá trị Sig, không dựa vào bảng mô tả
- Bảng Descriptives và biểu đồ chỉ có vai trò minh họa
- Không suy luận chủ quan từ trung bình nếu kiểm định không có ý nghĩa
Phân tích phương sai giúp nhà nghiên cứu đưa ra kết luận khoa học, tránh suy đoán cảm tính.
7. Vai trò của kiểm định phương sai ANOVA trong nghiên cứu
Kiểm định phương sai ANOVA là công cụ cốt lõi trong:
- Nghiên cứu hành vi khách hàng
- Đánh giá hiệu quả chính sách
- So sánh nhóm trong nghiên cứu xã hội học
Việc sử dụng đúng kiểm định phương sai ANOVA giúp nâng cao độ tin cậy và giá trị học thuật của nghiên cứu.
8. Kết luận
Kiểm định phương sai ANOVA là phương pháp không thể thiếu khi cần so sánh nhiều nhóm. Khi thực hiện đúng quy trình, kiểm soát giả thuyết và đọc kết quả chính xác, one way ANOVA sẽ cung cấp bằng chứng thống kê vững chắc cho nghiên cứu của bạn.
Nếu bạn cần hỗ trợ thực hành kiểm định phương sai ANOVA, xử lý dữ liệu SPSS hoặc tư vấn Xử lý số liệu, hãy tham khảo:

Các loại biến trong nghiên cứu khoa học dễ hiểu
Trong bất kỳ đề tài nào, việc xác định đúng các loại biến trong nghiên cứu khoa học là nền tảng quan trọng quyết định chất lượng mô hình nghiên cứu và kết quả phân tích dữ liệu. Rất nhiều sinh viên và người mới làm nghiên cứu gặp khó khăn vì nhầm lẫn vai trò giữa các biến, dẫn đến mô hình sai, phân tích sai và kết luận không có giá trị.
Bài viết này giúp bạn hiểu rõ các loại biến trong nghiên cứu khoa học theo cách đơn giản, logic và dễ áp dụng, bao gồm: biến độc lập, biến phụ thuộc, biến trung gian, biến điều tiết và mối liên hệ với biến định tính định lượng.
Vì sao cần hiểu rõ các loại biến trong nghiên cứu khoa học?

Trong nghiên cứu định lượng, mô hình nghiên cứu thực chất là mô hình hóa mối quan hệ giữa các biến. Nếu xác định sai các loại biến trong nghiên cứu khoa học, bạn sẽ gặp các vấn đề như:
- Mô hình nghiên cứu thiếu logic
- Không kiểm định được giả thuyết
- Kết quả hồi quy, SEM, EFA không có ý nghĩa
Do đó, hiểu đúng bản chất và vai trò của từng loại biến là yêu cầu bắt buộc.
Biến độc lập trong nghiên cứu khoa học
Biến độc lập là biến đóng vai trò tác động, giải thích hoặc gây ra sự biến thiên của các biến khác trong mô hình.
Trong các loại biến trong nghiên cứu khoa học, biến độc lập thường là trọng tâm của giả thuyết nghiên cứu.
Đặc điểm của biến độc lập:
- Có thể có một hoặc nhiều biến độc lập trong một mô hình
- Có thể tác động trực tiếp hoặc gián tiếp đến biến phụ thuộc
- Có thể là biến định tính định lượng
Ví dụ:
- Thu nhập → sự hài lòng
- Chất lượng dịch vụ → ý định mua lại
Biến phụ thuộc
Biến phụ thuộc là biến chịu tác động bởi các biến khác trong mô hình nghiên cứu.
Trong hệ thống các loại biến trong nghiên cứu khoa học, biến phụ thuộc chính là biến phản ánh kết quả hoặc mục tiêu nghiên cứu.
Đặc điểm:
- Có thể có một hoặc nhiều biến phụ thuộc
- Là biến được giải thích trong mô hình
- Thường là biến định lượng, nhưng cũng có thể là định tính
Ví dụ:
- Mức độ hài lòng
- Ý định mua hàng
- Hiệu quả công việc
Biến trung gian (Mediating Variable)
Biến trung gian là biến đóng vai trò cầu nối giữa biến độc lập và biến phụ thuộc.
Trong các loại biến trong nghiên cứu khoa học, biến trung gian giúp giải thích cơ chế tác động của biến độc lập lên biến phụ thuộc.
Mô hình trung gian phổ biến:
A → B → C
Trong đó B là biến trung gian.
Đặc điểm của biến trung gian:
- Có thể có một hoặc nhiều biến trung gian
- Có thể tồn tại nhiều cấp trung gian (A → B → C → D)
- Thường được kiểm định bằng hồi quy hoặc SEM
Ví dụ:
- Chất lượng dịch vụ → Sự hài lòng → Ý định mua lại
Biến điều tiết (Moderating Variable)
Biến điều tiết là biến làm thay đổi mức độ hoặc hướng tác động giữa hai biến khác trong mô hình.
Trong nhóm các loại biến trong nghiên cứu khoa học, biến điều tiết không tác động trực tiếp mà tác động thông qua việc thay đổi mối quan hệ.
Biểu diễn khái quát:
X → Y (phụ thuộc vào Z)
Đặc điểm:
- Có thể là biến định tính hoặc định lượng
- Một biến điều tiết có thể điều tiết nhiều mối quan hệ
- Thường kiểm định bằng biến tương tác
Ví dụ:
- Thu nhập điều tiết mối quan hệ giữa giáo dục và mức sống
- Giới tính điều tiết mối quan hệ giữa quảng cáo và ý định mua
Biến kiểm soát (Control Variable)
Biến kiểm soát là biến được đưa vào mô hình để loại trừ ảnh hưởng nhiễu, giúp kết quả phản ánh đúng tác động của biến độc lập lên biến phụ thuộc.
Trong các loại biến trong nghiên cứu khoa học, biến kiểm soát không phải là trọng tâm giả thuyết.
Đặc điểm:
- Có thể là biến định tính hoặc định lượng
- Thường là đặc điểm cá nhân
- Giúp mô hình ổn định hơn
Ví dụ:
- Giới tính
- Độ tuổi
- Trình độ học vấn
Mối liên hệ với biến định tính định lượng
Biến định tính định lượng không phải là vai trò trong mô hình mà là cách phân loại dữ liệu của biến.
Trong các loại biến trong nghiên cứu khoa học:
- Biến độc lập có thể là định tính hoặc định lượng
- Biến phụ thuộc thường là định lượng
- Biến trung gian và biến điều tiết có thể thuộc cả hai dạng
Việc xác định đúng loại dữ liệu giúp lựa chọn phương pháp phân tích phù hợp.
Những lỗi thường gặp khi xác định các loại biến
- Nhầm lẫn giữa biến trung gian và biến điều tiết
- Đưa biến kiểm soát thành biến độc lập
- Không phân biệt vai trò và loại dữ liệu của biến
Những lỗi này rất phổ biến và có thể làm hỏng toàn bộ mô hình nghiên cứu.
Kết luận
Hiểu đúng các loại biến trong nghiên cứu khoa học là bước đầu tiên và quan trọng nhất khi xây dựng mô hình nghiên cứu. Việc phân biệt rõ biến độc lập, biến phụ thuộc, biến trung gian, biến điều tiết và mối liên hệ với biến định tính định lượng giúp nghiên cứu có cơ sở khoa học và giá trị thực tiễn.
Nếu bạn đang gặp khó khăn trong việc xác định biến, xây dựng mô hình nghiên cứu hoặc xử lý dữ liệu trên SPSS, bạn có thể tham khảo thêm tài liệu tại xulysolieu.info – Xử lý số liệu hoặc liên hệ 0878968468 để được hỗ trợ chi tiết.

Sơ đồ quy trình nghiên cứu khoa học chuẩn
Sơ đồ quy trình nghiên cứu là nội dung nền tảng mà bất kỳ người học sau đại học, sinh viên năm cuối hay nhà nghiên cứu nào cũng cần nắm vững trước khi triển khai luận văn, luận án hoặc đề tài khoa học. Việc hiểu đúng giúp bạn tránh làm nghiên cứu theo cảm tính, đảm bảo tính logic, tuần tự và có giá trị học thuật.
Bài viết này trình bày sơ đồ quy trình nghiên cứu khoa học chuẩn gồm 6 bước, được sử dụng phổ biến trong các nghiên cứu kinh tế – xã hội hiện nay, đặc biệt là nghiên cứu định lượng và nghiên cứu ứng dụng.
Sơ đồ quy trình nghiên cứu là gì?
Sơ đồ quy trình nghiên cứu là cách mô hình hóa toàn bộ các bước thực hiện một nghiên cứu khoa học từ lúc hình thành ý tưởng cho đến khi hoàn thiện báo cáo nghiên cứu. Thay vì làm rời rạc từng phần, sơ đồ giúp người nghiên cứu nhìn thấy bức tranh tổng thể của quy trình nghiên cứu khoa học.
Một sơ đồ chuẩn thường thể hiện rõ:
- Trình tự các bước nghiên cứu
- Mối liên kết giữa lý thuyết – dữ liệu – phân tích
- Điểm bắt đầu và điểm kết thúc của nghiên cứu
Tổng quan sơ đồ quy trình nghiên cứu khoa học

Theo thực hành phổ biến, sơ đồ quy trình khoa học gồm 6 bước chính:
- Tiếp cận nghiên cứu
- Xác định vấn đề nghiên cứu
- Thiết kế nghiên cứu
- Thu thập dữ liệu
- Phân tích dữ liệu
- Kết luận và báo cáo nghiên cứu
Mỗi bước trong quy trình nghiên cứu đều có vai trò riêng và liên kết chặt chẽ với nhau.
Bước 1 – Tiếp cận nghiên cứu
Bước đầu tiên trong sơ đồ quy trình nghiên cứu là xác định lý do thực hiện nghiên cứu. Người nghiên cứu cần trả lời các câu hỏi:
- Tại sao nghiên cứu này cần thiết?
- Vấn đề thực tiễn hoặc học thuật là gì?
- Nghiên cứu giúp giải quyết điều gì cho doanh nghiệp hoặc tổ chức?
Kết quả của bước này là hình thành lý do nghiên cứu, bao gồm lý do thực tiễn và lý do lý thuyết – nền tảng cho toàn bộ sơ đồ quy trình nghiên cứu.
Bước 2 – Xác định vấn đề nghiên cứu
Ở bước này, sơ đồ quy trình nghiên cứu yêu cầu người nghiên cứu xác định rõ:
- Mục tiêu nghiên cứu (tổng quát và cụ thể)
- Câu hỏi nghiên cứu
- Đối tượng và phạm vi nghiên cứu
- Ý nghĩa khoa học và thực tiễn
Đồng thời, cần xác định kết cấu nghiên cứu phù hợp. Với nghiên cứu định lượng, kết cấu 5 chương thường được áp dụng. Với nghiên cứu định tính, kết cấu 3 chương phổ biến hơn.
Bước 3 – Thiết kế nghiên cứu
Thiết kế nghiên cứu là bước trung tâm trong sơ đồ quy trình nghiên cứu. Nội dung chính gồm:
- Xác định cơ sở lý thuyết và mô hình nghiên cứu
- Lược khảo nghiên cứu trong và ngoài nước
- Xác định khe hổng nghiên cứu
- Đề xuất giả thuyết nghiên cứu
Đây là bước thể hiện rõ tính học thuật và mức độ đóng góp mới của nghiên cứu trong sơ đồ quy trình nghiên cứu.
Bước 4 – Thu thập dữ liệu
Thu thập dữ liệu là bước chuyển từ lý thuyết sang thực nghiệm trong sơ đồ quy trình nghiên cứu. Công việc bao gồm:
- Xác định tổng thể và đơn vị chọn mẫu
- Lựa chọn phương pháp chọn mẫu
- Xác định cỡ mẫu
- Tiến hành khảo sát và mã hóa dữ liệu
Dữ liệu có thể là dữ liệu sơ cấp (khảo sát) hoặc dữ liệu thứ cấp (báo cáo, thống kê).
Bước 5 – Phân tích dữ liệu
Phân tích dữ liệu là bước quyết định chất lượng nghiên cứu trong sơ đồ quy trình nghiên cứu. Nội dung gồm:
- Phân tích thống kê mô tả
- Kiểm định độ tin cậy thang đo (Cronbach’s Alpha)
- Phân tích nhân tố EFA, CFA
- Phân tích hồi quy, SEM, ANOVA
Kết quả phân tích dữ liệu dùng để kiểm định giả thuyết và đánh giá mô hình nghiên cứu đã đề xuất.
Bước 6 – Kết luận và báo cáo nghiên cứu
Bước cuối cùng trong sơ đồ quy trình nghiên cứu là tổng hợp và trình bày kết quả. Nội dung bao gồm:
- Kết luận chính của nghiên cứu
- Hàm ý quản trị và giải pháp đề xuất
- Hạn chế nghiên cứu
- Hướng nghiên cứu tiếp theo
Báo cáo nghiên cứu cần đảm bảo logic, nhất quán với các bước trước trong sơ đồ quy trình nghiên cứu.
Ý nghĩa của sơ đồ quy trình nghiên cứu
Việc xây dựng đúng sơ đồ quy trình giúp:
- Đảm bảo tính khoa học và hệ thống
- Giảm sai sót trong quá trình làm luận văn
- Tăng khả năng bảo vệ và công bố nghiên cứu
Đây là lý do sơ đồ quy trình luôn được yêu cầu trình bày rõ ràng trong luận văn và luận án.
Kết luận
Sơ đồ quy trình là kim chỉ nam cho toàn bộ hoạt động nghiên cứu khoa học. Khi nắm vững từng bước từ tiếp cận nghiên cứu, thiết kế nghiên cứu, thu thập dữ liệu, phân tích dữ liệu đến báo cáo nghiên cứu, bạn sẽ triển khai đề tài một cách logic, chặt chẽ và hiệu quả.
Nếu bạn cần hỗ trợ xây dựng sơ đồ quy trình nghiên cứu, thiết kế nghiên cứu hoặc Xử lý số liệu, bạn có thể tham khảo tại:
Bảng Chi-Square và các phân phối thường dùng
Trong thống kê suy luận, bảng chi-square là một công cụ cực kỳ quan trọng giúp nhà nghiên cứu đưa ra kết luận về kiểm định độc lập, mức độ phù hợp của dữ liệu và mối quan hệ giữa các biến định tính. Nếu bạn từng làm việc với bảng chéo, khảo sát hoặc phân tích dữ liệu phân loại, chắc chắn bạn sẽ phải sử dụng bảng chi-square.
Bài viết này sẽ giúp bạn hiểu rõ bảng chi square là gì, nguồn gốc từ phân phối xác suất Chi-Square, cách sử dụng chi square table, cách xác định giá trị tới hạn chi square và ứng dụng trong các bài kiểm định độc lập một cách dễ hiểu, thực tế.
1. Kiểm định Chi-Square là gì?
Kiểm định Chi-Square (χ²) là một họ các phương pháp kiểm định giả thuyết thống kê, trong đó thống kê kiểm định tuân theo phân phối xác suất Chi-Square nếu giả thuyết không (H0) là đúng.
Trong thực hành phân tích dữ liệu, kiểm định Chi-Square thường được dùng để:
- Kiểm tra tính độc lập thống kê giữa hai biến định tính
- Kiểm tra mức độ phù hợp giữa dữ liệu quan sát và dữ liệu kỳ vọng
Để đưa ra kết luận, nhà nghiên cứu bắt buộc phải đối chiếu kết quả kiểm định với bảng chi square.
2. Các dạng kiểm định Chi-Square phổ biến
Trước khi đi sâu vào bảng chi square, bạn cần biết một số dạng kiểm định Chi-Square thường gặp:
- Kiểm định chi bình phương Pearson (phổ biến nhất)
- Kiểm định chi bình phương Yates (hiệu chỉnh cho mẫu nhỏ)
- Kiểm định chi bình phương Mantel–Haenszel
Trong hầu hết các nghiên cứu xã hội, kinh tế và marketing, kiểm định Pearson là dạng được sử dụng nhiều nhất và cũng là dạng gắn liền với chi square table.
3. Công thức thống kê Chi-Square
Thống kê kiểm định Chi-Square có dạng:
χ² = Σ (O − E)² / E
Trong đó:
- O: tần số quan sát (observed frequency)
- E: tần số kỳ vọng (expected frequency)
Giá trị χ² càng lớn thì mức độ sai khác giữa dữ liệu quan sát và dữ liệu kỳ vọng càng cao. Tuy nhiên, để biết giá trị đó có đủ lớn để bác bỏ giả thuyết hay không, bạn phải so sánh nó với giá trị tới hạn chi square trong bảng chi square.
4. Bảng Chi-Square là gì?

Bảng chi square (hay chi square table) là bảng thống kê cung cấp các giá trị tới hạn chi square ứng với từng mức ý nghĩa (α) và bậc tự do (df).
Nói cách khác, bảng chi square cho bạn biết:
- Ngưỡng bao nhiêu thì kết quả kiểm định được xem là có ý nghĩa thống kê
- Khi nào nên bác bỏ giả thuyết không
Nếu không sử dụng bảng chi square, bạn sẽ không thể kết luận đúng trong các bài kiểm định.
5. Phân phối xác suất Chi-Square
Bảng chi square được xây dựng dựa trên phân phối xác suất Chi-Square (χ² distribution).
Đặc điểm của phân phối Chi-Square:
- Chỉ nhận giá trị không âm (≥ 0)
- Lệch phải
- Hình dạng phụ thuộc vào bậc tự do (df)
Khi bậc tự do tăng lên, phân phối Chi-Square dần tiệm cận phân phối chuẩn.
6. Bậc tự do và vai trò trong bảng Chi-Square
Một yếu tố bắt buộc khi sử dụng bảng chi square là xác định đúng bậc tự do (degrees of freedom – df).
Trong kiểm định độc lập với bảng chéo r × c:
df = (r − 1)(c − 1)
Bậc tự do càng lớn thì giá trị tới hạn chi square càng cao.
7. Cách đọc bảng Chi-Square từng bước
Bước 1: Xác định mức ý nghĩa (α)
Mức ý nghĩa thường dùng:
- α = 0.10
- α = 0.05 (phổ biến nhất)
- α = 0.01
Bước 2: Xác định bậc tự do (df)
Tính df dựa trên số nhóm hoặc số ô trong bảng chéo.
Bước 3: Tra bảng chi square
Tại giao điểm giữa df và mức α, bạn sẽ tìm được giá trị tới hạn chi square.
Bước 4: So sánh với χ² tính toán
- Nếu χ² tính > χ² tới hạn → bác bỏ H0
- Nếu χ² tính ≤ χ² tới hạn → không bác bỏ H0
Đây là cách sử dụng bảng chi square chuẩn trong mọi giáo trình thống kê.
8. Bảng Chi-Square và kiểm định độc lập
Ứng dụng phổ biến nhất của bảng chi square là kiểm định độc lập giữa hai biến định tính.
Ví dụ:
- Giới tính và hành vi mua hàng
- Trình độ học vấn và mức thu nhập
- Độ tuổi và mức độ hài lòng
Trong các trường hợp này, chi square table giúp bạn xác định xem hai biến có mối liên hệ thống kê hay không.
9. Điều kiện áp dụng kiểm định Chi-Square
Để sử dụng đúng bảng chi square, dữ liệu cần thỏa mãn:
- Dữ liệu dạng tần số
- Các quan sát độc lập
- Tần số kỳ vọng mỗi ô ≥ 5 (với kiểm định Pearson)
Nếu điều kiện bị vi phạm, kết quả kiểm định và việc tra bảng chi square có thể không còn chính xác.
10. Kết luận
Bảng chi square là công cụ nền tảng trong thống kê suy luận, giúp nhà nghiên cứu diễn giải kết quả kiểm định độc lập và đánh giá mối quan hệ giữa các biến định tính.
Việc hiểu rõ bảng chi square, chi square table, phân phối xác suất Chi-Square và giá trị tới hạn chi square sẽ giúp bạn tránh được nhiều sai lầm nghiêm trọng trong phân tích dữ liệu.
Nếu bạn đang gặp khó khăn trong việc đọc bảng, tra giá trị tới hạn hoặc xử lý dữ liệu thống kê trên SPSS, bạn có thể tham khảo thêm các bài hướng dẫn chuyên sâu tại xulysolieu.info – Xử lý số liệu hoặc liên hệ 0878968468 để được hỗ trợ trực tiếp.

Hàm hồi quy mẫu: Cách xác định và diễn giải
Hàm hồi quy mẫu là khái niệm trung tâm trong phân tích hồi quy và kinh tế lượng, đóng vai trò cầu nối giữa dữ liệu quan sát thực tế và mối quan hệ lý thuyết của tổng thể. Trong thực tế nghiên cứu, chúng ta hầu như không bao giờ có dữ liệu của toàn bộ tổng thể mà chỉ làm việc với dữ liệu mẫu. Vì vậy, việc hiểu đúng bản chất hàm hồi quy mẫu là điều kiện bắt buộc để diễn giải chính xác kết quả hồi quy.
Bài viết này trình bày rõ ràng khái niệm hàm hồi quy mẫu, mối quan hệ giữa hàm hồi quy mẫu và hàm hồi quy tổng thể, cách xác định, ước lượng và diễn giải trong bối cảnh hồi quy tuyến tính.
1. Từ hàm hồi quy tổng thể đến hàm hồi quy mẫu
Trong lý thuyết kinh tế lượng, mối quan hệ giữa biến phụ thuộc Y và biến độc lập X trong tổng thể được mô tả bởi hàm hồi quy tổng thể (Population Regression Function – PRF):
E(Y | X = Xi) = β1 + β2Xi
Tuy nhiên, các tham số β1, β2 là tham số tổng thể và không thể quan sát trực tiếp. Do đó, khi chỉ có dữ liệu mẫu, chúng ta phải xây dựng hàm hồi quy mẫu để ước lượng mối quan hệ này.
2. Hàm hồi quy mẫu là gì?
Hàm hồi quy mẫu (Sample Regression Function – SRF) là hàm hồi quy được ước lượng từ dữ liệu mẫu nhằm xấp xỉ hàm hồi quy tổng thể chưa biết. Dạng tổng quát của hàm hồi quy mẫu trong hồi quy tuyến tính đơn là:
Ŷi = β̂1 + β̂2Xi
Trong đó:
- β̂1: ước lượng mẫu của tung độ gốc
- β̂2: ước lượng mẫu của độ dốc
- Ŷi: giá trị dự đoán của Y tại quan sát i
Như vậy, hàm hồi quy mẫu là kết quả trực tiếp của quá trình ước lượng mẫu.
3. Bản chất ngẫu nhiên trong hàm hồi quy mẫu

Một điểm quan trọng cần hiểu là: trong phân tích hồi quy, biến độc lập X được xem là xác định, còn biến phụ thuộc Y là biến ngẫu nhiên có điều kiện theo X.
Với cùng một mức X = Xi, nếu lấy mẫu nhiều lần, ta có thể quan sát được nhiều giá trị Y khác nhau do:
- Bỏ sót biến giải thích
- Sai số đo lường
- Tác động ngẫu nhiên không dự đoán trước
- Dạng hàm mô hình chưa hoàn hảo
Do đó, sai lệch giữa Yi và Ŷi được gọi là sai số hồi quy:
Yi = β̂1 + β̂2Xi + ei
Trong đó ei là sai số ngẫu nhiên của hàm hồi quy mẫu.
4. Mối quan hệ giữa hàm hồi quy mẫu và hàm hồi quy tổng thể
Hàm hồi quy mẫu là sự xấp xỉ của hàm hồi quy tổng thể. Nếu mẫu đủ lớn và các giả định hồi quy được thỏa mãn, các ước lượng β̂1, β̂2 sẽ tiến gần đến β1, β2.
Nói cách khác:
- PRF: mô tả mối quan hệ thật sự trong tổng thể
- SRF: mô tả mối quan hệ ước lượng từ dữ liệu mẫu
Do đó, chất lượng của hàm hồi quy mẫu phụ thuộc trực tiếp vào chất lượng dữ liệu mẫu và phương pháp ước lượng.
5. Hàm hồi quy mẫu trong hồi quy tuyến tính
Trong hồi quy tuyến tính, hàm hồi quy mẫu có dạng đường thẳng, trong đó:
- β̂1 xác định vị trí đường hồi quy
- β̂2 xác định mức độ thay đổi của Y khi X thay đổi một đơn vị
Ví dụ: nếu β̂2 = 0.6, điều này cho thấy khi X tăng 1 đơn vị, Y dự kiến tăng trung bình 0.6 đơn vị theo hàm hồi quy mẫu.
6. Diễn giải kết quả từ hàm hồi quy mẫu
Khi diễn giải hàm hồi quy mẫu, cần lưu ý:
- Ŷi là giá trị kỳ vọng có điều kiện, không phải giá trị quan sát thực tế
- Sai số ei phản ánh phần biến thiên chưa giải thích được
- Không suy diễn quan hệ nhân quả nếu không có cơ sở lý thuyết
Việc diễn giải đúng hàm hồi quy mẫu giúp tránh các kết luận sai lệch trong nghiên cứu khoa học.
7. Ý nghĩa thực tiễn của hàm hồi quy mẫu
Hàm hồi quy mẫu được sử dụng rộng rãi trong:
- Phân tích kinh tế: tiêu dùng – thu nhập, đầu tư – lãi suất
- Nghiên cứu xã hội: giáo dục – thu nhập
- Phân tích dữ liệu kinh doanh và marketing
Nhờ hàm hồi quy mẫu, nhà nghiên cứu có thể dự báo, kiểm định giả thuyết và ra quyết định dựa trên dữ liệu thực tế.
8. Kết luận
Hàm hồi quy mẫu là nền tảng của phân tích hồi quy hiện đại. Việc hiểu đúng bản chất sample regression function, vai trò của ước lượng mẫu và mối quan hệ với hàm hồi quy tổng thể giúp bạn sử dụng hồi quy tuyến tính một cách chính xác và khoa học.
Nếu bạn cần hỗ trợ học tập, Xử lý số liệu hoặc phân tích hồi quy từ dữ liệu mẫu, bạn có thể tham khảo tại:

Reverse Coding là gì? Cách đảo chiều thang đo đúng cách
Trong nghiên cứu định lượng, đặc biệt là các nghiên cứu sử dụng bảng hỏi khảo sát, reverse coding (đảo đáp án, đảo chiều thang đo) là một kỹ thuật rất quan trọng nhưng thường bị hiểu sai hoặc thực hiện không đúng. Nếu không xử lý reverse coding chính xác, thang đo rất dễ vi phạm tính đơn hướng, dẫn đến hệ số Cronbach’s Alpha thấp, thậm chí làm thang đo mất hoàn toàn ý nghĩa.
Bài viết này sẽ giúp bạn hiểu rõ reverse coding là gì, vì sao cần sử dụng, cách thiết kế câu hỏi nghịch đảo, cách đảo chiều thang đo Likert và cách xử lý SPSS reverse đúng chuẩn trong phân tích dữ liệu khảo sát.
1. Reverse coding là gì?
Reverse coding là kỹ thuật đảo chiều điểm số của một câu hỏi trong thang đo, thường được áp dụng cho các câu hỏi nghịch đảo trong bảng khảo sát.
Về bản chất, reverse coding không làm thay đổi nội dung câu hỏi, mà chỉ thay đổi cách mã hóa điểm số để đảm bảo tất cả các biến quan sát trong cùng một nhân tố đều cùng chiều (thuận chiều).
Ví dụ với thang đo Likert 5 mức:
- 1 → Rất không đồng ý
- 2 → Không đồng ý
- 3 → Bình thường
- 4 → Đồng ý
- 5 → Rất đồng ý
Khi thực hiện reverse coding, điểm số sẽ được đảo như sau:
- 5 → 1
- 4 → 2
- 3 → 3
- 2 → 4
- 1 → 5
2. Vì sao cần sử dụng reverse coding?
Reverse coding được sử dụng với hai mục đích chính trong xử lý dữ liệu khảo sát.
2.1. Phát hiện bảng khảo sát kém chất lượng
Trong thực tế, không ít đáp viên trả lời khảo sát một cách qua loa, đánh cùng một mức điểm cho tất cả câu hỏi mà không đọc nội dung.
Bằng cách đưa vào một câu hỏi nghịch đảo, nhà nghiên cứu có thể phát hiện các câu trả lời mâu thuẫn.
Ví dụ:
- Câu thuận chiều: “Tôi hài lòng với mức lương hiện tại”
- Câu nghịch chiều: “Tôi không hài lòng với mức lương hiện tại”
Nếu đáp viên chọn 4–5 cho cả hai câu, khả năng cao đây là phiếu khảo sát không nghiêm túc.
2.2. Đảm bảo tính đơn hướng của thang đo
Trong một nhân tố, tất cả các biến quan sát phải cùng chiều (đều tích cực hoặc đều tiêu cực). Nếu không xử lý reverse coding, thang đo sẽ vi phạm tính đơn hướng và làm giảm độ tin cậy.
3. Tính thuận chiều, nghịch chiều trong thang đo Likert
Trước khi áp dụng reverse coding, bạn cần hiểu rõ khái niệm thuận chiều và nghịch chiều trong thang đo Likert.
- Thuận chiều: điểm càng cao → mức độ càng tích cực
- Nghịch chiều: điểm càng cao → mức độ càng tiêu cực
Một nhân tố chỉ được phép chứa các biến quan sát cùng chiều. Nếu có biến nghịch chiều, bắt buộc phải thực hiện đảo chiều thang đo.
4. Thiết kế câu hỏi nghịch đảo đúng cách
Câu hỏi nghịch đảo không phải là câu hỏi “đánh đố”, mà là câu hỏi có nội dung tương đồng với một câu khác nhưng mang ý nghĩa ngược lại.
Nguyên tắc thiết kế:
- Chỉ chọn 1–2 câu trong mỗi nhân tố để đảo chiều
- Nội dung phải rõ ràng, tránh phủ định kép
- Không dùng quá nhiều câu hỏi nghịch đảo
Việc lạm dụng reverse coding có thể khiến đáp viên rối và trả lời sai.
5. Thời điểm thực hiện reverse coding

Reverse coding chỉ được thực hiện trong giai đoạn xử lý dữ liệu khảo sát, không phải trong giai đoạn thu thập dữ liệu.
Quy trình chuẩn:
- Thu thập dữ liệu gốc từ bảng khảo sát
- Loại bỏ các phiếu khảo sát mâu thuẫn
- Thực hiện reverse coding cho các câu nghịch đảo
- Phân tích dữ liệu (Cronbach’s Alpha, EFA, hồi quy…)
Trong luận văn và báo cáo kết quả, không trình bày nội dung câu hỏi nghịch đảo hay thao tác đảo mã.
6. Cách đảo chiều thang đo Likert
Với thang đo Likert 5 mức, quy tắc đảo chiều thang đo chuẩn là:
| Giá trị gốc | Sau reverse coding |
|---|---|
| 1 | 5 |
| 2 | 4 |
| 3 | 3 |
| 4 | 2 |
| 5 | 1 |
Đối với thang đo 7 mức hoặc 10 mức, nguyên tắc tương tự, lấy giá trị lớn nhất + 1 trừ đi giá trị gốc.
7. Reverse coding trong SPSS (SPSS reverse)
Trong SPSS reverse, bạn có thể thực hiện reverse coding bằng các cách sau:
- Transform → Recode into Same Variables
- Transform → Recode into Different Variables (khuyến nghị)
Cách an toàn nhất là recode sang biến mới để tránh mất dữ liệu gốc.
Ví dụ:
- Old Value: 1 → New Value: 5
- Old Value: 2 → New Value: 4
- Old Value: 3 → New Value: 3
- Old Value: 4 → New Value: 2
- Old Value: 5 → New Value: 1
8. Những lỗi thường gặp khi reverse coding
- Quên đảo chiều trước khi chạy Cronbach’s Alpha
- Đảo chiều sai quy tắc
- Đưa câu hỏi nghịch đảo vào phần trình bày kết quả
- Lạm dụng quá nhiều câu hỏi nghịch đảo
Những lỗi này đều có thể khiến kết quả phân tích sai lệch nghiêm trọng.
9. Kết luận
Reverse coding là một kỹ thuật nhỏ nhưng có vai trò rất lớn trong xử lý dữ liệu khảo sát. Việc hiểu đúng và thực hiện đúng reverse coding giúp đảm bảo tính đơn hướng của thang đo, nâng cao độ tin cậy và chất lượng nghiên cứu.
Nếu bạn gặp khó khăn khi đảo chiều thang đo, xử lý SPSS reverse, hoặc các kiểm định thống kê bị vi phạm, bạn có thể tham khảo thêm tài liệu tại xulysolieu.info – Xử lý số liệu hoặc liên hệ 0878968468 để được hỗ trợ trực tiếp.
Bảng kiểm định T: Cách tra và đọc kết quả
Bảng kiểm định t là công cụ không thể thiếu khi thực hiện kiểm định t-test trong thống kê và nghiên cứu khoa học. Đối với nhiều người mới học phân tích dữ liệu, việc hiểu và sử dụng bảng kiểm định t thường gây nhầm lẫn do liên quan đến các khái niệm như phân phối t, giá trị tới hạn, mức ý nghĩa và bậc tự do.
Bài viết này giúp bạn hiểu bản chất bảng kiểm định t, cách tra bảng một cách hệ thống và cách đọc kết quả kiểm định t-test sao cho đúng chuẩn học thuật và dễ áp dụng trong thực tế.
1. Kiểm định t-test và vai trò của bảng kiểm định t
Kiểm định t-test là phương pháp thống kê dùng để so sánh trung bình của:
- Một mẫu với một giá trị cho trước
- Hai mẫu độc lập
- Hai mẫu có liên hệ (cặp đôi)
Trong tất cả các trường hợp trên, bảng kiểm định t được sử dụng để xác định giá trị tới hạn t, từ đó đưa ra quyết định bác bỏ hay chấp nhận giả thuyết thống kê.
2. Bảng kiểm định t là gì?
Bảng kiểm định t (hay t distribution table) là bảng tra cứu các giá trị tới hạn của phân phối t-Student tương ứng với từng bậc tự do và mức ý nghĩa.
Phân phối t được sử dụng thay cho phân phối chuẩn khi:
- Cỡ mẫu nhỏ (thường n < 30)
- Phương sai tổng thể chưa biết
- Dữ liệu xấp xỉ phân phối chuẩn
Trong các tình huống này, việc sử dụng bảng kiểm định t là bắt buộc nếu không dùng trực tiếp p-value từ phần mềm.
3. Cấu trúc của bảng kiểm định t

Một bảng kiểm định t tiêu chuẩn thường gồm:
- Cột bên trái: bậc tự do (degrees of freedom – df)
- Các cột bên phải: giá trị t ứng với các mức ý nghĩa khác nhau
Các mức ý nghĩa thường gặp trong bảng kiểm định t:
- α = 0.10
- α = 0.05 (phổ biến nhất)
- α = 0.01
- α = 0.001
4. Bậc tự do trong bảng kiểm định t
Bậc tự do là thông số quan trọng khi tra bảng kiểm định t. Cách xác định bậc tự do phụ thuộc vào loại kiểm định t-test:
- One-Sample T-Test: df = n − 1
- Independent-Sample T-Test: df = n1 + n2 − 2
- Paired-Sample T-Test: df = n − 1
Nếu xác định sai bậc tự do, việc tra bảng kiểm định t sẽ dẫn đến kết luận sai.
5. Mức ý nghĩa và giá trị tới hạn t
Mức ý nghĩa (α) là xác suất chấp nhận sai lầm loại I, tức là bác bỏ giả thuyết không khi giả thuyết không là đúng. Khi tra bảng kiểm định t, mức ý nghĩa quyết định cột giá trị tới hạn cần sử dụng.
Giá trị tới hạn t là ngưỡng so sánh với giá trị t tính toán:
- |ttính| ≥ ttới hạn → bác bỏ H0
- |ttính| < ttới hạn → không bác bỏ H0
Đây là nguyên tắc cốt lõi khi sử dụng bảng kiểm định t.
6. Cách tra bảng kiểm định t từng bước
Để sử dụng bảng kiểm định t chính xác, bạn thực hiện theo các bước:
- Xác định loại kiểm định t-test
- Tính bậc tự do (df)
- Chọn mức ý nghĩa α
- Tìm dòng df trong bảng
- Tìm cột α tương ứng
- Đọc giá trị tới hạn t
Sau đó, so sánh giá trị t tính toán với giá trị tra được từ bảng kiểm định t.
7. Bảng kiểm định t và kiểm định một phía – hai phía
Khi sử dụng bảng kiểm định t, cần phân biệt:
- Kiểm định hai phía: chia mức ý nghĩa α cho 2
- Kiểm định một phía: dùng trực tiếp α
Ví dụ: nếu kiểm định hai phía với α = 0.05, bạn cần tra cột 0.025 trong bảng kiểm định t.
8. Mối liên hệ giữa bảng kiểm định t và p-value
Trong các phần mềm như SPSS, kết quả kiểm định t-test thường trả về p-value. Tuy nhiên, việc hiểu bảng kiểm định t giúp:
- Kiểm tra lại logic kết quả
- Hiểu bản chất thống kê thay vì chỉ đọc p-value
- Diễn giải kết quả đúng trong luận văn, bài báo
Trong thực hành học thuật, bảng kiểm định t vẫn được giảng dạy song song với p-value để củng cố tư duy thống kê.
9. Lưu ý khi sử dụng bảng kiểm định t
- Luôn xác định đúng bậc tự do
- Không nhầm giữa kiểm định một phía và hai phía
- Không dùng t-test khi dữ liệu vi phạm nghiêm trọng giả định chuẩn
- Không lạm dụng t-test cho nhiều nhóm (nên dùng ANOVA)
Sử dụng sai bảng kiểm định t là một trong những lỗi phổ biến nhất của người mới học thống kê.
10. Kết luận
Bảng kiểm định t là nền tảng để hiểu và thực hiện đúng kiểm định t-test. Khi nắm vững cách xác định bậc tự do, mức ý nghĩa và giá trị tới hạn t, bạn có thể tự tin đưa ra kết luận thống kê chính xác và khoa học.
Nếu bạn cần hỗ trợ học tập, Xử lý số liệu hoặc thực hiện kiểm định t-test, có thể tham khảo tại:
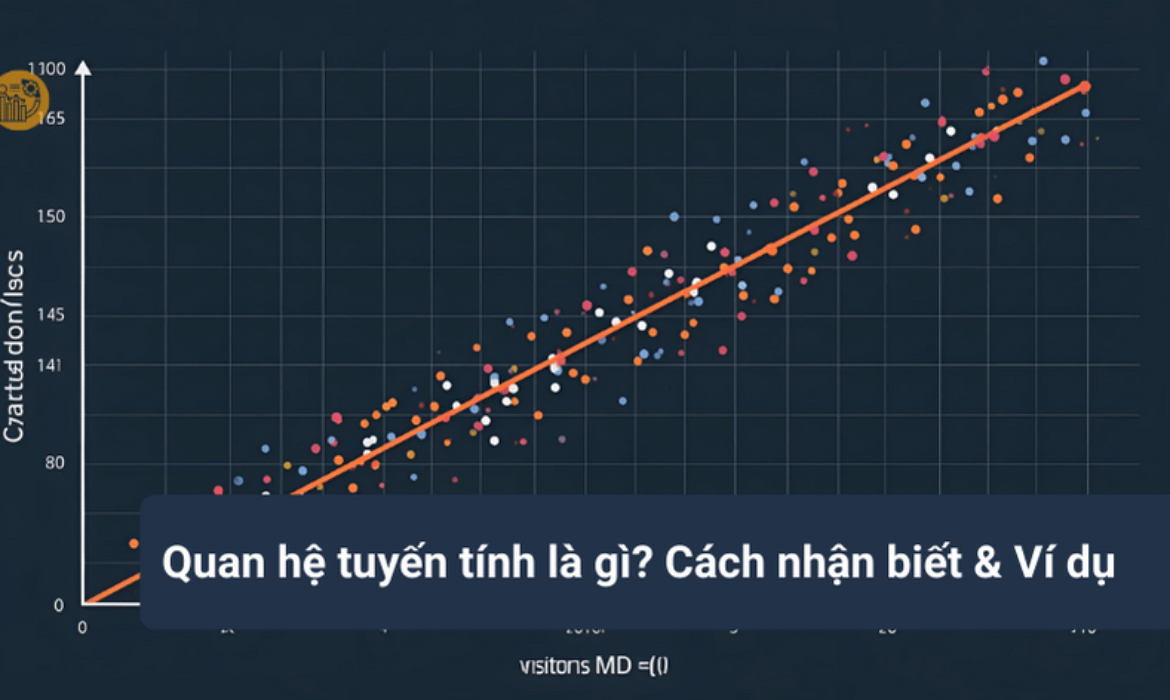
Quan hệ tuyến tính là gì? Cách nhận biết và ví dụ
Trong phân tích dữ liệu và thống kê, một trong những câu hỏi quan trọng nhất là: quan hệ tuyến tính là gì và làm thế nào để nhận biết mối quan hệ đó giữa các biến? Hiểu đúng quan hệ tuyến tính là gì giúp bạn đọc đúng dữ liệu, lựa chọn phương pháp phân tích phù hợp và xây dựng mô hình dự báo hiệu quả.
Bài viết này sẽ giúp bạn hiểu rõ quan hệ tuyến tính là gì theo cách đơn giản, gắn với thực tiễn phân tích dữ liệu, đồng thời làm rõ các khái niệm liên quan như mối quan hệ tuyến tính, tương quan tuyến tính, đồ thị scatter plot, hệ số tương quan và hồi quy tuyến tính.
1. Quan hệ tuyến tính là gì?

Quan hệ tuyến tính là gì? Đó là mối quan hệ giữa hai biến mà khi một biến thay đổi thì biến còn lại thay đổi theo một quy luật gần như đường thẳng. Nói cách khác, mức tăng (hoặc giảm) của biến này tỷ lệ tương đối đều với mức tăng (hoặc giảm) của biến kia.
Trong toán học và thống kê, quan hệ tuyến tính là gì thường được biểu diễn dưới dạng:
Y = aX + b
Trong đó:
- X: biến độc lập
- Y: biến phụ thuộc
- a: hệ số góc (mức độ ảnh hưởng)
- b: hằng số
Đây chính là nền tảng của mối quan hệ tuyến tính trong phân tích dữ liệu.
2. Mối quan hệ tuyến tính trong thực tế
Trong đời sống và nghiên cứu, quan hệ tuyến tính là gì có thể được minh họa bằng nhiều ví dụ quen thuộc:
- Thu nhập tăng → chi tiêu tăng
- Số giờ học tăng → điểm số tăng
- Chi phí quảng cáo tăng → doanh thu tăng
Tất nhiên, không phải lúc nào dữ liệu cũng hoàn toàn “thẳng hàng”, nhưng nếu xu hướng chung là đường thẳng thì ta vẫn xem đó là mối quan hệ tuyến tính.
3. Tương quan tuyến tính là gì?
Khi tìm hiểu quan hệ tuyến tính là gì, bạn sẽ thường gặp khái niệm tương quan tuyến tính.
Tương quan tuyến tính đo lường mức độ chặt chẽ của mối quan hệ tuyến tính giữa hai biến. Nó cho biết hai biến có cùng tăng, cùng giảm hay ngược chiều nhau, và mức độ mạnh hay yếu của mối quan hệ đó.
Tương quan tuyến tính thường được đo bằng hệ số tương quan (ký hiệu r).
4. Hệ số tương quan và ý nghĩa

Hệ số tương quan có giá trị trong khoảng từ -1 đến 1:
- r > 0: tương quan tuyến tính dương
- r < 0: tương quan tuyến tính âm
- r ≈ 0: không có hoặc rất yếu mối quan hệ tuyến tính
Giá trị tuyệt đối của r càng gần 1 thì quan hệ tuyến tính là gì càng rõ ràng và mạnh.
Lưu ý quan trọng: tương quan không đồng nghĩa với quan hệ nhân quả. Hai biến có tương quan tuyến tính mạnh chưa chắc biến này gây ra biến kia.
5. Nhận biết quan hệ tuyến tính bằng đồ thị scatter plot
Một cách trực quan và phổ biến để xác định quan hệ tuyến tính là gì là sử dụng đồ thị scatter plot.
Scatter plot (đồ thị phân tán) biểu diễn mỗi quan sát dữ liệu bằng một điểm trên mặt phẳng tọa độ. Dựa vào hình dạng phân bố của các điểm, ta có thể nhận biết:
- Các điểm nằm gần một đường thẳng đi lên → quan hệ tuyến tính dương
- Các điểm nằm gần một đường thẳng đi xuống → quan hệ tuyến tính âm
- Các điểm phân tán ngẫu nhiên → không có mối quan hệ tuyến tính rõ ràng
Trong phân tích dữ liệu, scatter plot thường là bước đầu tiên để khám phá mối quan hệ tuyến tính trước khi đi vào mô hình hóa.
6. Quan hệ tuyến tính và hồi quy tuyến tính
Khi đã hiểu rõ quan hệ tuyến tính là gì, bước tiếp theo là xây dựng hồi quy tuyến tính.
Hồi quy tuyến tính là phương pháp dùng để mô hình hóa mối quan hệ tuyến tính giữa biến phụ thuộc và biến độc lập. Mục tiêu của hồi quy tuyến tính là:
- Ước lượng mức độ ảnh hưởng của X lên Y
- Dự báo giá trị Y khi X thay đổi
- Kiểm định giả thuyết nghiên cứu
Mô hình hồi quy tuyến tính đơn giản có dạng:
Y = aX + b + ε
Trong đó ε là sai số ngẫu nhiên.
7. Phân biệt quan hệ tuyến tính mạnh và yếu
Không phải cứ tồn tại mối quan hệ tuyến tính là mô hình hồi quy sẽ tốt. Cần phân biệt:
- Quan hệ tuyến tính mạnh: hệ số tương quan lớn, scatter plot rõ xu hướng
- Quan hệ tuyến tính yếu: hệ số tương quan nhỏ, dữ liệu phân tán
Trong trường hợp quan hệ tuyến tính là gì không rõ ràng, bạn có thể cần xem xét biến đổi dữ liệu hoặc sử dụng mô hình phi tuyến.
8. Những sai lầm thường gặp khi hiểu quan hệ tuyến tính
Khi mới học, nhiều người thường mắc các sai lầm sau:
- Nhầm lẫn giữa tương quan và quan hệ nhân quả
- Cho rằng mọi mối quan hệ đều là tuyến tính
- Bỏ qua việc kiểm tra bằng scatter plot
Vì vậy, để hiểu đúng quan hệ tuyến tính là gì, bạn cần kết hợp cả trực quan (đồ thị) và định lượng (hệ số tương quan, hồi quy).
9. Kết luận
Quan hệ tuyến tính là gì là một khái niệm cốt lõi trong thống kê và phân tích dữ liệu. Nó giúp chúng ta hiểu cách các biến liên hệ với nhau, làm nền tảng cho tương quan tuyến tính, hồi quy tuyến tính và các mô hình dự báo.
Việc nhận biết đúng mối quan hệ tuyến tính thông qua đồ thị scatter plot và hệ số tương quan sẽ giúp bạn phân tích dữ liệu chính xác và hiệu quả hơn.
Nếu bạn đang học hoặc thực hành phân tích dữ liệu, hãy tham khảo thêm các bài viết chuyên sâu tại xulysolieu.info – Xử lý số liệu hoặc liên hệ 0878968468 để được hỗ trợ chi tiết.

Mô Hình OLS: Định Nghĩa & Ứng Dụng trong hồi quy
Mô hình OLS (Ordinary Least Squares) là nền tảng quan trọng nhất của phân tích hồi quy trong kinh tế lượng và thống kê ứng dụng. Hầu hết các phương pháp phân tích định lượng nâng cao đều bắt nguồn từ hoặc mở rộng dựa trên mô hình OLS. Vì vậy, việc hiểu đúng bản chất, giả định và cách diễn giải kết quả của mô hình này là yêu cầu bắt buộc đối với người làm nghiên cứu khoa học và phân tích dữ liệu.
Bài viết này trình bày một cách hệ thống về mô hình OLS, từ định nghĩa, công thức, giả định mô hình, quy trình ước lượng cho đến các ứng dụng thực tiễn trong hồi quy tuyến tính.
1. Mô hình OLS là gì?
Mô hình OLS là phương pháp ước lượng các tham số của mô hình hồi quy tuyến tính bằng cách tối thiểu hóa tổng bình phương sai số hồi quy giữa giá trị quan sát và giá trị dự đoán. Nói cách khác, OLS tìm ra đường thẳng (hoặc siêu phẳng trong trường hợp nhiều biến) phù hợp nhất với dữ liệu.
Trong tiếng Anh, mô hình OLS được gọi là Ordinary Least Squares, nhấn mạnh nguyên lý “bình phương tối thiểu”.
2. Công thức toán học của mô hình OLS
Với hồi quy tuyến tính đơn giản, mô hình OLS được biểu diễn như sau:
Yi = β0 + β1Xi + εi
Trong đó:
- Yi: biến phụ thuộc tại quan sát i
- Xi: biến độc lập
- β0: hằng số (intercept)
- β1: hệ số hồi quy
- εi: sai số hồi quy
Mục tiêu của ước lượng OLS là tìm các giá trị β̂0 và β̂1 sao cho:
∑(Yi − Ŷi)² là nhỏ nhất
Đây chính là bản chất cốt lõi của mô hình OLS.
3. Ý nghĩa của sai số hồi quy trong mô hình OLS
Trong thực tế, biến độc lập không thể giải thích hoàn toàn biến phụ thuộc. Phần chênh lệch giữa giá trị thực tế và giá trị dự đoán được gọi là sai số hồi quy.
Trong mô hình OLS, sai số hồi quy đại diện cho:
- Các yếu tố bị bỏ sót
- Sai số đo lường
- Biến động ngẫu nhiên
Việc xử lý và kiểm soát sai số hồi quy là điều kiện quan trọng để mô hình có ý nghĩa thống kê.
4. Các giả định mô hình OLS
Để ước lượng OLS có tính không chệch và hiệu quả, giả định mô hình sau cần được thỏa mãn:
4.1. Tuyến tính
Mối quan hệ giữa biến phụ thuộc và biến độc lập phải tuyến tính theo tham số.
4.2. Kỳ vọng sai số bằng 0
E(εi) = 0, đảm bảo mô hình không bị chệch.
4.3. Đồng nhất phương sai
Phương sai của sai số hồi quy là không đổi (homoscedasticity).
4.4. Không tự tương quan
Sai số hồi quy của các quan sát phải độc lập với nhau.
4.5. Không đa cộng tuyến hoàn hảo
Các biến độc lập không được có quan hệ tuyến tính hoàn hảo.
Nếu các giả định mô hình bị vi phạm, kết quả của mô hình OLS có thể không còn đáng tin cậy.
5. Quy trình ước lượng OLS

Một quy trình ước lượng OLS chuẩn thường gồm các bước:
- Thu thập và làm sạch dữ liệu
- Xác định dạng mô hình hồi quy tuyến tính
- Ước lượng hệ số bằng phương pháp OLS
- Kiểm định các giả định mô hình
- Diễn giải kết quả
Quy trình này được áp dụng xuyên suốt trong các phần mềm thống kê như SPSS, Stata, R.
6. Mô hình OLS dạng log-log
Một biến thể phổ biến của mô hình OLS là dạng log-log, trong đó cả biến phụ thuộc và biến độc lập đều được logarit hóa:
ln(Yi) = β0 + β1ln(Xi) + εi
Trong mô hình này, hệ số β1 được hiểu là độ co giãn (elasticity), tức là Y thay đổi bao nhiêu phần trăm khi X thay đổi 1%.
Dạng log-log giúp mô hình OLS phù hợp hơn với các mối quan hệ tỷ lệ và giảm hiện tượng phương sai thay đổi.
7. Ứng dụng của mô hình OLS
Mô hình OLS được sử dụng rộng rãi trong nhiều lĩnh vực:
- Kinh tế học: phân tích tiêu dùng, thu nhập, GDP
- Tài chính: đánh giá tác động của lãi suất, rủi ro
- Xã hội học: nghiên cứu giáo dục, thu nhập, hành vi
- Kinh doanh: phân tích doanh thu, quảng cáo
Nhờ tính đơn giản và khả năng diễn giải rõ ràng, mô hình OLS luôn là lựa chọn đầu tiên trong phân tích hồi quy.
8. Ưu điểm và hạn chế của mô hình OLS
Ưu điểm
- Dễ ước lượng và dễ diễn giải
- Nền tảng cho nhiều mô hình nâng cao
- Phù hợp với dữ liệu định lượng
Hạn chế
- Nhạy cảm với ngoại lệ
- Phụ thuộc mạnh vào giả định mô hình
- Không phù hợp với quan hệ phi tuyến phức tạp
9. Kết luận
Mô hình OLS là công cụ cốt lõi trong hồi quy tuyến tính và phân tích dữ liệu định lượng. Việc hiểu rõ ordinary least squares, ước lượng OLS, giả định mô hình và sai số hồi quy giúp người nghiên cứu sử dụng mô hình đúng cách và đưa ra kết luận đáng tin cậy.
Nếu bạn cần hỗ trợ học tập, chạy hồi quy hoặc Xử lý số liệu chuyên sâu, có thể tham khảo tại:


